Author Archive
ComScore predictions versus Google performance actuals

One of my favorite bloggers, Paul Kedrosky, writes about the recent positive quarter by Google: Why Was Everyone Wrong-sided on Google?.
He summarizes:
- Comscore data had people convinced that first-quarter paid click data was disastrous
- It
just made sense that online ad spending would be cut, especially given
financial services dependency, and Google has to be hurt if/when that
happens - Google missed (sort of last quarter), and everyone assumed the wheel had come off and stayed off
I wrote about the problems with panel-based measurement in a much earlier blog (November 2006) titled Are you using Alexa numbers? (Probably).
In it, I discuss several problems, some which specifically apply to Alexa, and some which apply to comScore as well. Then I go through the different ways that these panel-based measurement providers try to rebalance their data, using extra sources like ISP-level info, normalizing based on global demographic info, and using random-digit dial (RDD) to collect data. I hadn’t read it in a while, but thought I’d dig it up for people who haven’t seen it.
Net/net, while many analysts missed their mark on Google’s projections, let me leave with a related thought:
What does it mean that these same, somewhat flawed approaches are driving the decisions of media buyers in a $40B+ global advertising industry?
:-)
Great stats on social media usage from an ad agency
Apologies for the light blogging, I’ve been tied up in Ad:Tech activities… (jk!)
I thought I’d share these recent slides from Universal McCann, one of the big ad agencies – there’s some good numbers in here about global usage of social networking sites, activities, etc. Pretty interesting info.
Quick link: Long-tail private jets using agent-based simulations
Great article in The Atlantic this month: Taxis in the Sky.
I’ve played with some of the toolkits there are out there in the past – here’s a toolkit called MASON multiagent simulation toolkit. I looked at them when I wrote some academic papers on simulating weaknesses in P2P networks – fun times.
MySpace versus Facebook: Winning in the US, Losing internationally

MySpace versus Facebook, Fight!
Several months ago, I bet my friend Arjun (then at Zillow, now at Facebook) that MySpace would continue to dominate Facebook. At the time, MySpace had 109M uniques per month, and Facebook had 47M uniques. While Facebook was growing faster at the time, MySpace had such a large multiple that I thought it was unlikely Facebook would catch up.
Yesterday I pulled up some stats, and found some interesting info:
Here’s the US chart of uniques, MySpace versus Facebook:

And here’s the global numbers for MySpace versus Facebook:

Wow.
Couple observations:
- Both MySpace and Facebook seem to have reached some form of saturation in the US – both sites seem to have plateau’d, with MySpace having 2X the uniques of Facebook
- Internationally, Facebook has narrowed the gap to the point where it’s almost the bigger site – absent the recent couple months, where there’s been a plateau
- Of course, a corollary two above observations is that most of Facebook’s new traffic is coming from overseas – from a monetization perspective, that’s a bad thing btw
This tells you how hard it is to extrapolate from past data – from my previous mathematical models of web traffic, as you reach saturation on acquireable audiences, it becomes harder and harder fight the plateau effect. That’s why oftentimes it’s easier to focus on acquiring brand new audiences (like internationally) rather than fix something that’s not working here in the US.
A test of the above paragraph is to watch the Facebook traffic – if it’s unable to beat the plateau without fundamentally re-inventing the product, it’ll mean that the site has hit its high water mark and won’t be able to ever beat MySpace monthly unique levels in the US. (Which is all that matters for big brand advertising anyway)
Side thought: If MySpace is losing internationally, I wonder if it’s because MySpace is more distinctly "American" than Facebook, where the latter has more of a utilitarian feel that might be more applicable horizontally across cultures?
Side thought #2: I wonder if MySpace is continuing to beat Facebook in the US because the audience it represents a wider "mass media" audience than Facebook. Maybe MySpace::Facebook like People Magazine::Wired? See image below:

Woohoo, broke 3,000 subscribers today! New readers: Feel free to intro yourselves

Hi everyone,
Good news – just broke through 3k users yesterday for the first time! I’m sure it’ll go up and down in the next while, but it’s always great to see a new high water mark:

Here’s how long it took me to get to this number – I started this blog about a year and change ago:
- zero to 500: 9 months
- 1000: 3 months
- 3000: 3 months
The big jump from 1000 to 3000 was accomplished through a link from Robert Scoble, who has an amazing amount of traffic – far more than any link I’ve ever gotten from TechMeme, Delicious, YC News, or the like.
Anyway, if you’re one of the new readers, feel free to shoot me a couple lines about yourself at voodoo [at] gmail. I’m always interested in hearing what folks are up to!
regards,
Andrew
Ads should be next to brand-elevating content
I’ve written in the past about brand advertisers being uncomfortable with having their ads show up next to social network ad impressions. Anyway, I ran into a funny slideshow I wanted to share.
Here are some hilarious examples of bad "editorial adjacency," some from retail, internet, and outdoor media:
Quick link on quant trading strategies
Great article, worth reading for those who have an interest in quantitative finance:
The New Math – Alpha Magazine.
5 factors that determine your advertising CPM rates
An interesting post at Techcrunch: Pubmatic Data Suggests Small Sites Command Higher Rates For Remnant Ads Than Large Sites.
I love seeing this cross-site ad monetization data, since it’s rare to get your hands on it unless you work for an ad network. For people outside the ad industry, advertising CPMs seem like black-boxes.
How to guess CPMs – 5 factors
At Revenue Science, a regular game of mine was to eyeball a site and guesstimate the CPMs.
A couple of the factors that I’d use:
- Is the site “sticky” or is it a one-hit wonder (like a reference site)?
- Is the site pretty general, or is it in a particular category (like cars)?
- Who uses the site? Everyone (including international) or just US?
- How dependent is the site on Google SEO versus a community site that draws people back?
- How many pageviews does the site have? Is it a lot? Or is it a small amount
Easy to monetize, hard to monetize
For the people who are curious, this is the easiest to monetize:
One-hit wonder site that exist in a particular category, are based in the US, and have lots of search traffic
In particular, your site is likely to have high CTRs since people are in a “transactional” mode. If you have all of those, and have a ton of pageviews, then you’ll make a ton of money.
The hardest to monetize?
Highly sticky sites that are general (like communication), based 100% outside of the US/Europe/Japan, with lots of pageviews
In a setup like this, not only are people unlikely to want to buy anything, even if they did, there’d be no way to make money off of this group.
Example categories
As a rough rule of thumb, I’d typically guess the following – these are very rough approximations, just to illustrate a couple points:
- Social sites (forums/chat/etc) without direct ad sales teams: <$0.25 CPM
- Largely international sites: <$0.50 CPM
- Medium-sized sites that use banner ad networks: <$1 CPM
- Reference sites in a specific category: >$5 CPM or sometimes much higher, depending on category – we ran into home improvement reference sites that did $20 CPMs
Because we were mostly dealing with so-called “remnant” advertising, these numbers are likely to be at the bottom of the range for these sites. That is, social networks might quote a CPM of $20 CPM, but what they really mean is that 1% of their inventory is sold at that, and the rest of the 99% is sold at <$0.25 prices.
As you can see, as a website property, you fall into either of two categories:
- Horizontal sites used daily which command low CPMs with huge pageviews
- Vertical sites that capture user intent – often used intermittently (with lots of traffic from search) with high CPMs and low pageviews
Horizontal sites, when scaled up to a large enough site, can employ direct ad sales teams that raise the CPM by a significant amount, but the entire process is demand-constrained.
Google is lucky to be both horizontal and vertical – it’s used everyday by people, but also captures user intent.
As stated before, social networks monetize poorly
Of course, sites with lots of pageviews are often ones that are general, are sticky, and have lots of context-less social content. I’ve written up a broader discussion of social network monetization at “5 things that make your social network monetize like crap.”
Back to small sites versus large sites
Now, the Techcrunch article discusses the idea that small sites monetize better than large ones. I think that’s actually a correlation rather than a causation. There are a ton of small sites out there, and much of their traffic comes from Google. It’s much harder to build a functioning social site where people coming back daily than a site where people occassionally stumble on it through their search engine.
As a result, my guess is that the mindset of the typical user includes intent – and that makes all the diference.
Your ad-supported Web 2.0 site is actually a B2B enterprise in disguise

Doing a B2C is more fun than a B2B right?
A lot of folks are doing consumer internet startups because they think Web 2.0 startups are more fun. You can focus on the end user, make them happy, get traction, and go from there. Enterprise software companies (or their equivalent brethren, SaaS companies) are perceived as annoying because:
- You have to hire a big, inefficient sales team
- Your numbers depend on closing key deals (usually at the end of the quarter)
- You have to deal with annoying suit-wearing people who don’t talk geek
- You have to make your product better not through superior technology, but often through superior PR, sales operations, or other non-geek issues
Turns out that ultimately, you can’t escape all of the above, even in the consumer internet world. Let’s talk about why:
A quote from a guy who’s been there, done that
Ted Rheingold, CEO of Dogster and Catster, recently commented on post How NOT to calculate ad revenues:
I can still recall our early heady days when we forecast revenue
based upon our (over-calculated) pageviews and our expect (also
over-calculated) network CPM. You can imagine our frustration when the
network CPM was half what we hoped and they could only server us a
fraction of the impressions we requested. Note to anyone: only sites
with massive page serves can run a business on direct response ads.
In other words, unless you are a ridiculously huge consumer internet site, you have to build up your revenues through brand advertising sales. It’s very hard to just use ad networks like Google AdSense to sustain yourself – just do the math using 10 to 25 cent CPMs and you’ll quickly see why.
And brand advertising sales looks and feels exactly the same as enterprise sales, and has all the same annoying characteristics, including:
- You have to hire a big ad sales team, potentially with an expensive office in New York
- A small percentage of advertiser/agency relationships will supply a large chunk of your revenues. This means that "key deals" matter, and you will jump if they ask you to – for example University of Phoenix was worth $200MM/yr for AOL
- Everyone you talk to in the ad industry are not nerds – many come from traditional media backgrounds, again with a NY bias
- And fundamentally, brand advertising isn’t a tech game – it’s one based on great execution and great teams – so Silicon Valley tech companies often are at a disadvantage
The key thing here is: The users of your website are not really your customers.
Instead, the entire process of gathering eyeballs is just to sell to your ACTUAL customers, who are the ad agencies and advertisers. Get it? Your Web 2.0 consumer startup is actually a B2B that sells inventory to brand advertisers.
All your hard work is just to create B2B ad inventory
At an extreme, all the love and effort you put into your consumer internet product ultimately generates a commodity. All it does is generate ad impressions, which are sometimes rare enough to be sold at a premium to ad agencies. While many companies are able to exit with the monetization potential there, but not fulfilled (i.e. YouTube), for most companies that want to hit it big, they have to focus on the transition point between generating ad inventory and monetizing ad inventory.
This transition point is a big sticking point for companies, because the folks who are best at creating product specialize in consumer-centric skills like user experience, technology, and operations, whereas the skills needed for successful B2B ad sales revolve around issues like being able to sleep on airplanes, schmoozing with advertisers, speaking at panels, and other soft-skills.
How to avoid this mess
Of course, one way to completely sidestep these issues is to directly monetize your users – this is pretty hard, because you have to deal with transaction processing, coming up with something so compelling people will pay for it, and a number of other problems.
Net/net, the approaches here that align you directly with your customers are business models like:
- Subscriptions
- Virtual goods
- E-Commerce
- etc
While putting off ad monetization might be the easier thing to do in the short-run, the above business models may have useful characteristics of their own in the long-run.
Innovation from Asian-based social sites
Found on Noah Kagan’s blog – an interesting slide deck on new business models from Asia-based social networking sites. Definitely worth looking at.
How NOT to calculate ad revenue
I recently read an interesting article that included a Bear Stearns projection on in-video advertising:
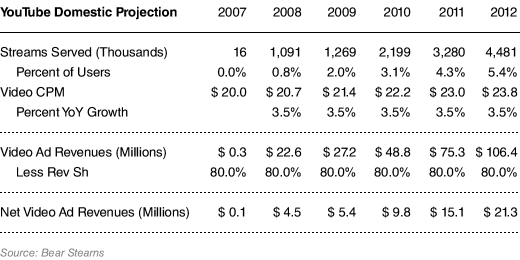
To quote the old guy in the Conan the Barbarian movie – WRONG!
In order to model out your CPMs, you should never ever do a straight calculation of:
Wrong revenue = CPM * impressions / 1000
The reason is that brand advertising is typically demand constrained – meaning that you need to field a big NYC-based sales team in order to do your sell, and as a result, you can only sell some percentage of your inventory. You can think of this process more like an enterprise sell, which scales revenue up with the number of sales folks you have.
Another corollary to this fact is that if you have a good CPM to start out with on one of these ad networks, don’t assume that the high CPM will continue as you scale up revenues. It’s easy to “tap out” ad networks, which gets you high CPM brand campaigns and turns into really crappy direct response campaigns.
Modeling brand ad sales as an enterprise sell
The right way to model out inventory is a number of equations – I’ll pretend that a site has two types of inventory, their “brand” stuff and their “direct response” (aka remnant) inventory:
Brand revenue = # campaigns sold * average campaign size * brand CPM
Direct response revenue = (total impressions – brand impressions) * remnant CPM
Total revenue = Brand + remnant revenue
In an actual forecast, you could get a ton more detail in the brand revenues side, since what you really care about is the # of ad sales people you have, how many campaigns they’re selling per quarter, the size, etc. Again, think of this as an enterprise sell, and treat it as such.
Similarly, if you were doing this for an entire site, you’d want more granularity. You’d approach this channel by channel, and do the CPMs and %s for each one. Inventory has different characteristics depending on ad placement, where you are in the usage of the site, and other factors. If you incorporate this into a grid, you can start to get a sense for how your different channels differ. That way, you can make the most accurate prediction possible.
Perhaps I’ll do a longer post on that at some point, with Excel spreadsheet attached ;-)
Faceoff between Facebook app analytics startups



New Facebook sub-sector
A sector has emerged recently that’s been interesting to follow – Facebook analytics companies.
These companies include:
It’ll be interesting to see where they go – I thought I’d elaborate a bit about the web analytics industry from my vantage point at digiMine, which later evolved into Revenue Science.
Evolution of web analytics companies
Early on the analytics space, there were a ton startups who wanted to get their hands on log files and pixel data. DigiMine was one of those companies, started by some data warehousing experts out of Microsoft led by Usama Fayyad (now Chief Data Officer at Yahoo). The idea was to do data analytics as a service, sucking in information about ecommerce, web traffic, as well as industry-specific data, and do all the math for companies – they were great at this.
Over time, however, the number of meaningful questions that customers wanted the analytics to answer went down – the focus became very much on web traffic, and specifically # of pageviews per day, # of sessions, and all the other common metrics you see on Google Analytics. As these metrics become more standard, then the customers (who were often larger F500 companies) started to buy based on "checklists" of features, rather than usability/UI, speed, or other important factors.
One problem for companies who took on the "high-end" approach of answering complex quesitons (often described as the most "powerful" queries) is that both the question and the answer elude the grasp of the end customer. If your end user doesn’t know how clustering algorithms work, it’s unlikely that they appreciate the value of software that does that for them, especially if there isn’t a direct ROI attached.
The space eventually devolved until a few winners emerged that satisfied the base requirements while supporting the infrastructure in a cheap, scaleable way.
What’ll happen in the Facebook analytics space?
If the Facebook analytics companies follow the same route, then you’ll see heavy competition as folks figure out what the core featureset required for the space. Once the basics are defined, then the next step will be for the companies who know how to scale the product to have a better cost model than everyone else.
Also, when doing a B2B infrastructure play, in a sense these small companies are taking a sector bet that all the apps in the Facebook economy will end up making some money. After all, if everyone’s just a small lifestyle play, there isn’t much revenue to go around in the apps world.
Net/net, the space seems like a challenging one – it’ll be fascinating to see where the web analytics analogy holds, and where it breaks. Analytics is seen as an important add-on and strategic entre into
other areas – will be interesting to see what emerges over time.
Search stats for this blog
I recently installed a Lijit add-on to the blog, and have gotten some interesting stats. Thought I’d share them below. Not surprisingly, there’s a ton of people searching about Facebook and viral marketing.
First, here are the searches that people do on the site:
- facebook 14 times
- registration funnel 7 times
- viral coefficient 7 times
- viral 7 times
- "meet new people" 5 times
- traction 5 times
- registration 4 times
- social gaming 3 times
- viral marketing 3 times
- dating site 2 times
- coefficient 2 times
- co-founder 2 times
- virtual goods 2 times
- yelp 2 times
- facebook viral 2 times
Second, these are the keywords for how people are searching for on Google and other search engines, in order to reach the site:
- andrew chen 127 times
- entrepreneur in residence 22 times
- andrew chen blog 20 times
- viral loop 18 times
- futuristic play 17 times
- futuristic 11 times
- vertical ad network 11 times
- "andrew chen" 9 times
- new diner games 9 times
- viral coefficient 8 times
- viral 8 times
- social networking monetization 7 times
- facebook quotes 6 times
- create a social network 5 times
- vertical ad networks 5 times
Web 2.0 Haikus
Sorry for the lack of posts recently, have been very busy in the last week.
I was at lunch with some friends and started typing out some viral marketing haikus on my phone – so secondly, sorry for the bad haikus that follow:
Viral marketing
Friends who spam you all the time
Aren’t really your friends
Just raised some V C
Social websites make no cash
Google can’t save you
Techcrunch Valleywag
Techmeme Mashable and more
Why work? Just read blogs
Fickle teenagers
Herded ruthlessly for cash
You got an invite
Lack of retention
Viral loops are not enough
You just jumped the shark
Please post your own in the comments ;-)
Reader question: What fuels you?
A: I think this YouTube video is appropriate:
What is best in life? (Conan the Barbarian)
Bridging your traffic engine with your revenue engine
Viral loops are only good for one thing
… and that thing ain’t revenue. Viral loops generate traffic, but you still need to:
- Retain the traffic that’s generated virally
- As well as also monetize the traffic
Between these steps are transition points from acquisition to retention, and then from retention to monetization. You can think of these transition points as a series of bridges (or more accurately, funnels) that you analyze and optimize.
Why separate your viral loop and your retention loop?
Some of you might have noticed that oftentimes, viral loops are extremely simple user flows that build on users’ need for:
- reciprocation (gifting, accepting invites)
- social norms (comparison/rating)
- greed (free ipods)
- etc.
For many of these loops, you can get a user to invite their next set of users, but after the process, it’s easy to feel a sense of completeness and leave the site. There are many Facebook apps, for example, that are just “pure” viral loops – there’s really no retention loop that the user enters after they’re done.
And as I argued in a previous post called “When and why do Facebook apps jump the shark?” the lack of a retention loop can hugely damage the long term value that you’re creating.
That said, the Shangri-La of viral marketing would be a product that not only was viral, but the viral loop was the same as a retention loop. Perhaps this is the easiest to do when you are building a communication app, because ultimately every time you use Hotmail, you are helping them advertise and acquire users.
But if you’re lazy, you can use one of the “pre-built” viral loops that are out there (like gifting, invitations, etc.) and try to integrate that into yoru site. You then have a viral loop that you use to acquire users, and after they’ve helped you acquire some traffic, you then transition them into a user experience that retains them.

HotOrNot case study
I want to use HotOrNot as an example of bridging your traffic engine with your revenue engine, because I think they do it very well. Please go to HotOrNot.com to refresh your memory, if you haven’t visited the site recently.
HoN is really split into two completely different experiences:
- The classic hot or not ratings experience
- Then, a dating site with virtual goods as the monetization
The first experience is the one that ultimately drives all the traffic. Without using any “productized” viral techniques, the site was viral because it was fun, and people sent it to their friends. This is their traffic engine, and for some companies, it might have been enough to slap some ads on the site and call it done.
However, the company went further than that – each picture on the site is actually an AD that bridges users into the dating site. At the top of each picture, you see “Click here to meet me,” but also clicking ANYWHERE on the picture also takes you into a registration landing page. Some % of users then convert on this page, and then successfully transition into a general dating site.
Why it works
There are some key things that make HotOrNot work, and I’d encourage you to think about it in the context of your web property also:
- HotOrNot has a novel user acquisition technique – user ratings that drive word-of-mouth viral
- The bridging process is tailored to work with the traffic engine, and thus is also very novel
- The traffic engine is bridged to the revenue engine via pictures that constitute 30%+ of the real estate on any given page
- Once you click, the picture of the person you’re interested in is used on the landing page to “smooth” the transition point and increase conversion rates
I think it’s very important that both the traffic engine, the bridge, and the retention loop are all motivationally aligned.” This means that if the user’s there for hot chicks, then the entire process bridges them into a retention loop that’s all about hot chicks. Or if it’s about making money, it permeates the entire funnel as well. HotOrNot has a very smoothly designed transition, as as a result, I’m sure the conversion rates are quite high.
Measuring the efficiency of your bridge
One might ask, how do you measure the smoothness of the transition? Well, consider the following – would you rather have:
Scenario A:
Acquire 1,000,000 users which turn into 10,000 retained users
or:
Scenario B:
Acquire 100,000 users which turn into 25,000 retained users?
It’s pretty obvious, of course, that acquiring LESS users but ending up with more retained users is better – thus I’d prefer scenario B. Because the carrying capacity on Facebook is roughly 60,000,000, then a more efficient bridge ultimately leads to more retained users, which generate much higher total visits, whcih in turn generate more revenue.
So let’s define a new metric, which I’ll call “Activation Efficiency,” using the marketing parlance of how many contacts you can “activate” into leads and then into sales:
Activation Efficiency = total retained users / total acquired users
where:
- Retained users means total # of users that had 2 visits or more, let’s say
- Acquired users means the total number of uniques that come in through your viral loop
Once you start measuring this, then it becomes much easier to think about connecting your viral loop and retention loops. After all, if you acquire 100 million users but only 0.1% activate, and you have a site of 100,000 active users, your ComScore numbers might look nice, but you’re right about to jump the shark!
Too many social networking aggregators?
OK, this is pretty funny. Check it out ;-)
Reader question: What’s the difference between “Viral Marketing” and “Word of Mouth?”
A: I tend to think of Viral Marketing that include both systematic and unsystematic ways that your current customers acquire new customers, including:
- Chain letters
- Tupperware parties
- Youtube embedding
- E-mail forwards
- Consumer “buzz”
- … etc
In some of these cases, the virality has been “built-in” to the system – for example, but chain letters explicitly promise you something in return for sending on a letter, as do Multi-Level Marketing systems like Tupperware. These incentives and systematic design are originated with the intent to propagate a viral process.
On the other hand, when I think of Word of Mouth, however, I specifically think of consumers telling other consumers about a product just because they like it, rather than there being a direct incentive to do so. This feels more organic or natural to me, and perhaps, it’s what people usually think of as your passionate influencers propelling your company forward.
Perhaps this distinction is arbitrary, but it helps serve the point that viral marketing can be defined very broadly – beyond word of mouth and other “natural” vectors.
Google’s second click versus Facebook’s second click

Google’s second click
For those of you who haven’t read Dave Morgan’s article on Google trying to capture the "second click" you should do so here: MediaPost – The Fight for the Second Click. It’s a couple months old, but worth the read if you haven’t seen it.
The point is, because of Google’s position as the de-facto start page of the internet, they are able to control where users go – and that control makes them powerful, because traffic = money. The fight for the "second click" refers to Google thinking about how they can control not just the first click (Search!) but also provide a shortcut to answer the query on a second click. And because of their control of the search engine result page (SERP), they can always place their content above everyone else’s.
Examples of capturing the second click
Here are a couple examples of this – check them out:
It might seem like a big deal to do this, but you can imagine that if you ran a business in weather, real estate, dictionary reference, or movies, you’d want to know where Google was planning to expand here.
The reason is that in a lot of these vertical businesses, like movies, your only hope for getting users to come back to your site is via search engines. It’s hard to have a daily relationship with your users, and thus you are dependent on the "start pages" to point you in the right direction.
So when you see Google starting to build into this area, it can cause trouble because it siphons away traffic.
Is the SERP Google’s platform?
When it comes to platforms, maybe it makes sense to think of the search result page as Google’s platform. After all, let’s compare to Microsoft:
- Windows is Microsoft’s horizontal platform across applications
- Applications build on top of Windows and have to adapt to its APIs
- Microsoft can use Windows to cross-sell their vertical apps (think Office, IE, XBox, etc)
- Back in the old school days, Microsoft could change their API or have "secret" APIs that would give their own applications an advantage over standalone companies
Let’s compare this to Google:
- The search results page is Google’s horizontal starting point across websites
- Websites build on top of the Google index and have to adapt to its algorithm changes – that industry is called Search Engine Optimization
- Google can use their search results page to cross-sell their vertical apps (think Google Toolbar, the mini-results listed above, etc.)
- Google changes tweaks their algorithms and put their own results above others, to give their own apps advantages over standalone companies
Again, the notion here is of controlling distribution – both platforms are able to cross-sell their applications and promote their usage in a way that undermines their competitors/partners that are at their mercy.
In fact, if anything, Google has been shy about using their SERPs to cross-promote their other products – which is why there’s so many Google products that don’t have much traffic to their competitors.
If Bill Gates ran Google, he’d probably cause all searches for "facebook" redirect to Orkut.com :-)
Comparing Google’s platform to Facebook’s
Facebook is in a similar position – like Google, they are one of the "start pages" of the internet. But rather than reference, they are focused on communication, which makes them one of the few sites on the internet people use every day. And like Google, people also leave their Facebook pages open all day, and thus, they can control access to subsequent pages.
Unlike Google, however, rather than sending users away from the site, Facebook opted to open up their website for application developers. Interestingly enough, what that means is that they control the first click, the second click, and maybe even the 50th click.
In this way, they are far more open than Google in letting people leverage their distribution, and allow developers to create rich functionality within the Facebook site. This may also be great for them because it causes far more dependence on their platform.
So let’s talk about what it’d mean for Google to open up their SERP, and treat it like their platform:
Google: Open up your SERP!
Right now, there are only two ways to build on top of the Google search experience:
- Buy text ads
- SEO your website and get into the organic index
And these are both great triggers for when people search for a specific type of text content.
But let’s run through a couple crazy "What If?" scenarios:
- What if Google let developers build INTO the search index pages with richer applications (like what Facebook/OpenSocial provides)?
- What if when you searched for "definition of ironic", it wasn’t a Google chosen result that came up at the top, but rather an "app" that placed itself there through driving the best relevance?
- What if Google created an open standard that allowed each result to return themselves not as an automatically processed paragraph of text, but as a rich application?
If these scenarios were possible, then you might argue that all the smart stuff that Google’s doing to improve their SERP – like making YouTube video thumbnails, or Google Image Search shortcuts – could be done automatically by the people building the underlying sites and integrating with a SERP API.
In fact, you could imagine that the ads could function this way as well, so that a real estate site might be given X by Y pixels of app real estate if they bid into the top slot.
Without this, the SERP is a walled garden platform that gets slow, incremental features based on whatever Google chooses to implement. And that’s the furthest thing from open, yet it’s also not Googley to let people clutter up the SERP. So we’ll see how this tension evolves over time ;-)
Rethinking Facebook’s “Daily Active Users”

What’s the key metric for Facebook apps?
You might recall that initially, Facebook apps were measured by installs, and shown on leaderboards as such, and as a result, people optimized for that.
These days, you see people quoting DAUs, meaning Daily Active Users.
Problem is, as I wrote in my last post on "When and why do Facebook apps jump the shark?" DAUs can still hide a festering retention problem underneath a very viral app. Ideally, you want something that gives you a sense for how good the retention is, regardless of how viral it is.
Viral apps can have inflated active user counts
As you might expect, as you are acquiring tons of users in a viral process, you can inflate the active user counts. That means:
DAU = users acquired through invites + users that are repeat users because they’re happy
… and ideally, you want to separate the two, and provide metrics to reflect the information. For the second term above, let’s call that "Daily Repeat Users"
How about "Daily Repeat Users?"
One way to do that is to use the cohort method, which I discuss in the jumping the shark article above, and also here. What you’d want to expose is what % of users, after getting exposed to the app one time are likely to come back and use it again.
As a result, you want to count users that come back MULTIPLE times, but subtract out first-time users.
You might also think about how to subtract out users who come back via notifications, or other shenanigans that app developers may use to boost this new metric. Obviously you’d expect some gaming either way – it’s inevitable with so much visibility at stake – but the more transparent the better.
If anyone has other suggestions for a better way to do this, I’m all ears!
Reader question: What are you working on?
Reader question: Does Facebook + performance ad network = awesome?
A: There are a couple interesting angles to consider here:
Facebook has a very interesting local play, due to their understanding of geographic and friendship networks. Very few companies in the world have as much information about your location and interests. However, the problem with local is mainly that the CPL to actually acquire a plumber in Tacoma, WA is often more than the revenue you’d ever get from it.
From the perspective of inside the Facebook site, I pretty much think it’ll be a grind-it-out brand ad sales play the same way Yahoo is. The more I think about Facebook, the more I think they are the new Yahoo – primarily strong in messaging and communication, they are more of a social utility than they are anything else. For them to succeed in generating significant revenues driving traffic to other sites, they have to move from a more people-oriented model to one where links to external sites play a bigger role in the interaction. That’ll be hard to do since it mucks with Facebook’s core mechanic.
And yet another angle is for Facebook to start their own performance ad network that places ads OFF of Facebook, as the reader suggests. This is absolutely feasible, but my guess is that any use of the information from on the site would cause a privacy nightmare for the company. I mean, it’s one thing to have Beacon which tracks data from OFF the site, but once you start trying to use data from on the site and giving it to any ol’ publisher to use, then you are in deep trouble. Obviously it’s likely that the privacy line is moving and evolving over time, but the public’s not ready for it now. (Even as companies like Fair Isaac, Axciom, etc are all mining even more sensitive information)
Even if the privacy implications were mitigated, how well would the Facebook ad network do? I’d think that with how smart their folks are, they could probably get somewhere quickly. However, remember that much of ads is not a technology problem – a lot of it as a sales execution problem – and that may not be where they want to spend their effort, even if they could be successful in the short run. After all, when you have a $15B valuation, picking up $100MM in revenue here or there may not be interesting if it’s hard to scale it up to $1B in revenue later on.
Reader question: Specialized resources for driving traffic?
A: I’m often pinged for requests to recruit for people who are great at viral marketing, or traffic generation, or the like. Here’s the quick answer to that, blogged for posterity:
- Because traffic is greatly valued right now, all the best people in viral marketing are off doing their own companies – in this list, I’d include the founders of Slide, RockYou, Hi5, Flixster, Tagged, etc. The short list of experts is probably around a dozen or two at most, and they are certainly all in San Francisco
- Obviously, anyone who says they are a viral marketing expert but runs a consulting firm probably doesn’t know what they’re doing, otherwise they would have their own destination site that they were growing. In many cases, they are experts in “word of mouth,” not the viral marketing techniques online that generate millions of users
- Since the science of quantitative viral marketing is new, few people have written about it, and in fact, the community as a whole is pretty secretive about the entire thing (for better or worse)
I think for the folks who are interested in viral marketing, the best place to start is to understand website metrics really really well. Then go read about the SEO industry, then learn about affiliate/leadgen practices (including optimization techniques), and then go study Facebook apps. It’d take a good 6-12 months to do (that’s about the time it took me), but once you’re done with it, you can really pick up a lot.
If you’re an engineer and actually like to build stuff, I’d be open to meeting folks here in SF – just shoot me a mail.
Reader question: First-time entrepreneurs
A: Here are the steps I’d follow:
- Move to San Francisco
- Meet investors that know how to judge first-time team in early stage situations
- Get funded, and start a company :)
Anyone who is having trouble doing this, particularly if you’re from an engineering background, please e-mail me and I am more than happy to help.
Reader question: What 5 blogs do you read regularly?
A: I read all the same blogs as everyone else – Techcrunch, Venturebeat, Mashable, GigaOm, etc. :)
I think more interesting is probably the places where I get information that’s “proprietary” that a lot of other people don’t spend too much time looking through. I’ll give a couple examples here:
- Talking to end users: I’m often recruiting users using Google Adwords, Facebook ads, MySpace messaging, or Craigslist in order to talk to them about how they use websites, what their day is like, what they are thinking about these days, etc. I’ve also gone out to odd places like Sacramento and Renton to talk to users that are substantially different than me
- Perusing through “bottoms up” internet reports: Going back to my ad days, I like to look at a bunch of reports from comScore, Nielsen, Alexa, Quantcast, etc., and come through dozens of pages of websites. I enjoy trying out new domains, if I don’t recognize them, as well as looking them up on WHOIS, trying to figure out who the founders are, etc.
- Creating queries for odd or unique terms: I have dozens of Google alerts set up for terms like “viral loop” or “viral coefficient” or “social gaming” or other key terms where if someone’s using it, I probably want to learn more about them or the topic
- Talking to people in other industries: Sometimes, you can find analogies in other industries that apply back to your own – I’m often talking to folks in Finance to get their quantitative perspective. I also talk to folks in the creative industries, like design, or writing, etc., because they have something specific to add. And I enjoy hearing from people in the advertising industry, both traditional and interactive, because their world is so different from the consumer internet world, yet the issues clearly apply. Same for games.
I think the worst thing you can do is to surround yourself with people who are too similar to you. It’s more fun to hang out with folks who are passionate about other things – just like the future-engineer kid who takes apart his dad’s toys and gets in trouble, I think you have to spend time dissecting the way other smart people think in order to develop the amateur psychology skills necessary to think about consumer behavior.
Facebook viral marketing: When and why do apps “jump the shark?”
Excel spreadsheet download
For those of you who are interested in the gory details, please download the following spreadsheet here:
Download: Viral and Retention Excel Model
Math warning!
This blog post will be a little more technical than usual, so I apologize to those of you who are bored by this. Anyway, let’s get started.
See this image before? Many would describe that as, EPIC FAIL ;-)

That’s what happens when you “jump the shark” and your app goes from successful to completely not successful. Why does this happens? This blog post is to dissect that exact issue.
Modeling user acquisition
First off, let’s look at some ways to model user acquisition. For those of you with the spreadsheet, this is the second tab. You first start with a couple constants:
- Invite conversion rate % = 10%
- Average invites per person = 8.00
- Initial user base = 10,000
- Carrying capacity = 100,000
(note that these are just example numbers)
To understand how these constants work, you basically want to think about how viral marketing works. What happens is that you start out with an initial userbase (=10k), and every time your userbase grows, each user ends up sending out invites (=8.00), which then have a specific conversion rate (=10%).
That means that in the first time period, you have 10k. In the second time period, you get 10k*8*10% more users, which equals 8k more users, who are the next round of users who send invites. Then in the third time period, it’s 8k*8*10%, and so on. Note that the new batch of users needs to exceed the previous batch, in order to “go viral.” That ratio is often referred to as the viral coefficient. In fact, here’s the equation for this unbounded viral equation:
u(t) = u(0) * (1 + i * conv)^t
where u(0) = 10k, i = 8.00, conv = 10%, and t is the # of time periods
However, note that this assumes that your “carrying capacity,” that is, how many users are in the total network, is unlimited. However, on Facebook, that’s not true – once you burn through the 60 million new users, then you don’t have any left. Similarly, it doesn’t reflect the reality that as you saturate the network, your invites may end up going towards people who have already evaluated or installed your app, and they are unlikely to install it again.
A simple model for network saturation
Thus, one simplifying assumption is that as you saturate the network, the conversion rate on your invites goes down. In one possible model, you’d argue:
- If you have installs on 0% of the network, then your natural conversion rate (10%) holds
- If you have installs on 50%, then your natural conversion rate is discounted 50%, which equals 5%
- If you have installs on 99%, then your natural conversion rate is discounted 99%, and etc.
Note that you might even argue that this is an optimistic view. You might argue, for example, that the “discount” on your conversion rate should be related to the total % of the userbase that’s been invited, not the total % that’s installed something.
In that version, if someone hates your app and doesn’t want to install it, it’s unlikely that they will ever install it. In the version I’m describing, the only people who won’t install your app are the people who have already done so.
To describe this mathematically, you might say that at each point, there’s an “adjusted conversion rate” which looks like:
adjusted conversion rate
= natural conversion rate * saturation %
= natural conversion rate * (1 – current installs / total Facebook population)
so if you agree that’s true, then you can combine the this last equation into the initial one:
u(t) can be defined as:
= u(0) * (1 + i * adjusted_conv)^t
= u(0) * (1 + i * conv * u(t-1) / carrying_capacity)^t
(This can then be simplified further, but I’ll leave the math to the reader – the spreadsheet reflects this thinking already)
As a result of this, you see that your cumulative install base kinda looks like a logistic curve:

Now that you see that the cumulative users follows an interesting trend, where it starts to grow exponentially, but then starts to hit saturation. Then it eventually takes some time, but it starts to plateau as you reach the carrying capacity of the network.
Quick break for Cohort analysis re-introduction
Before reading through this post, you might want to glance over a previous blog I wrote on cohort analysis and its relationship to user retention reports
You may want to read that before going further…
Back to our story…
Previously, I discussed how you can mathematically model the viral acquisition process, particularly as you hit the network saturation point. However, while the model shows a growth curve for cumulative users, it doesn’t take into account how retention metrics fit in.
In the spreadsheet linked above, you can flip to the “User retention” tab, which shows a cohort analysis perspective of the hypothetical site. Here’s how to read it:
- On the Y-axis are “Time period cohorts” which are defined by the group of users that joined in a particular time period. So #1 means, the users that joined in period #1
- On the X-axis are the “Time period” which defines the time period that the specific cohort is in
So for example, in 1×1, there are an initial 3,000 active users on the site.
However, by the next time period, the 3,000 active users have declined to 1,500 users. However, because there are a bunch of virally generated users, there’s a new cohort of 2,328 users who have joined as cohort 2. The number of “new” cohorts is defined by the rows in the other spreadsheet tab, “Viral acquisition.”
Then notice that at the bottom of each time period, there’s a count for how many users are active in total, in each specific time period.
Does this make sense? If not, shoot me an email at voodoo[at]gmail with what you’re confused by, and I’ll update this blog with more clarifications!
Introducing the retention coefficient
So the key driver for retention is the % of users that stay alive in a specific cohort, between one period to the next. If it’s 50%, then if you start out with 3k users, in the next period you’ll be left with 1.5k users. If it’s 100% retention, then 3k users ends up with 3k users.
So let’s play around with the numbers.
At 99% retention, which means that over 20 periods you are losing very few users, you get a graph of total active users that looks like this:

This chart looks pretty good, of course. You start with exponential growth, then hit a plateau, and you have a very slow burn on your userbase. I suspect that the Facebook site, among other highly popular sites, essentially have >99.999% retention between days. I say that because people seem to use the site for years at a time, and probably the early users of the site are probably mostly still on it.
Now for the EPIC FAIL.
OK, here’s the fun part, which is when you drop the retention coefficient down to 50%:

Ouch. Doesn’t look good. If you’ve read all the way this, far it’s pretty clear why this happens, but let’s summarize:
Key conclusion
The key in this calculation, if you look at the stats, is that:
- Early on, the growth of the curve is carried by the invitations
- However, over time the invitations start to slow down as you hit network saturation
- The retention coefficient affects your system by creating a “lagging indicator” on your acquisition – if you have good retention, even as your invites slow down, you won’t feel it as much
- If your retention sucks, then look out: The new invites can’t sustain the growth, and you end up with a rather dire “shark fin.”
Things look great at first, but if you can’t retain users long-term, then you don’t have a business.
Improvements to the model
I want to make a couple comments on how the simplified model contained within the spreadsheet could be improved dramatically:
- Don’t just model invites, model multiple viral channels
- Include “usage loops” not just the “invite loops,” which are triggered by users trying out the product
- Try both a global carrying capacity, as well as a “niche discount” for the number, if your app is super-niche and focused on a particular demographic or user behavior
- Be able to handle realistic numbers – perhaps even retrofit it onto Adonomics data, for example
- Factor in re-engagement channels
- etc.
Obviously if anyone would like to think about this more, feel free to and shoot me an email.
Facebook and Platforms conference: Graphing Social Patterns (San Diego) recap

Back from San Diego, and back from my blogging break
I was recently at the Graphing Social Patterns conference, where the illustrious Dave McClure of 500Hats and Justin Smith of Inside Facebook invited me to be on a panel on viral marketing. Thanks again Dave and Justin!
I wanted to write down a couple high-level observations I made from the conference, and then expand on them:
- Platforms opportunities are growing (but fragmenting)
- Is "jumping the Facebook shark" the new "jumping the Techcrunch shark?"
- Key verticals are starting to get defined, in particular "social gaming"
- Monetization can support "garage entrepreneurs," but venture returns are still elusive
More below…
Platform opportunities are growing (but fragmenting). Does run-anywhere mean succeed-anywhere?
The good news is that, for app developers, the choices for where they can build new widgets/apps is increasing over time. And more choices means that there’s more demand for app developers, and the leverage moves to them versus the platforms.
The best thing that happened for Slide and RockYou, when they were confronted with a hostile MySpace regarding their initial slideshow widget was for Facebook to open up. And now that platforms have aggregated a total of 250M+ users, they are in the business of courting developers – this means app developers will be able to get more leverage in the relationship when it comes to viral marketing, monetization, data portability, and other key issues.
That said, the problem is that more choice means more fragmentation. It’s yet to be seen whether OpenSocial will provide a consistent set of APIs, or if it’ll descend into buggy and slightly incompatible containers. Anyone who’s done development trying to support both IE6, IE7, Firefox, and Safari will know what I mean when it comes to supporting slightly compatible interfaces.
In particular, while the OpenSocial API provides specifications around key areas, it’s clear developers will still have to think through each particular social network design for issues like:
- viral channels and distribution
- app spamminess
- additional API extensions
- language localization and demographics
- audience “mindset” and usage context
After all, OpenSocial may allow apps to "run-anywhere," but not "succeed-everywhere."
I’m sure the players that will win in each specific social network will have to customize the entire app to integrate as tightly as possible into the underlying platform. In fact, this may open plenty of niches to form where the larger players (Slide/RockYou/etc) won’t pursue – net/net, this is probably great for the small teams that are just getting started
Is “jumping the Facebook shark” the new “jumping the TechCrunch shark”?
Now that apps have had significant run-time on the Facebook platform, several have shown that there’s a high-water mark for the DAU (daily active users). The reason is that a lot of companies focused on viral marketing early on, but even while they saturated the usersbase, they weren’t able to retain many of them.
Thus, when you do the math, what happens is that you have an exponential growth curve at first, which then plateaus out as you hit network saturation, and then turns into a shark fin as the bulk of your earlier users decays into nothingness. I will write much, much more on this model in a later post, and I even have an Excel spreadsheet to match!
Furthermore, it makes me wonder how much depth there is on the retention analytics side – after all, while a select group of developers have been building viral dashboards where they calculate viral factors, optimize their registration funnels, and so on, how many of them have been applying cohort analysis?
Key verticals are starting to get defined, in particular "social gaming"
There was a ton of discussion around the new "social gaming" category, and what that means. First off, the evolution of this space has been very interesting, and covered well by Jeremy Liew at Lightspeed. Ultimately, the group of Facebook developers who are working on these products are:
- Coming from the web side of the world, not the games industry
- Focused on games as a communication and social activity, not a 1-player experience
- Trying out mostly asynchronous, short time-commitment game designs
- And experimenting with monetization models beyond advertising, like virtual goods
There’s a ton of activity here, and it’ll be interesting to see how it develops, and ultimately how it bleeds out beyond Facebook.
Among the other verticals, there’s a bit of controversy as there are multiple types of apps with different characteristics, like:
- Deep and viral
- Deep but not viral
- Shallow and viral
- Shallow but not viral
I bolded "Deep but not viral" and "Shallow and viral" because it seems like many of the apps being developed are either one of the other. The guys making deep apps who are trying to deliver real utility, and some of them with actual business models, are having trouble acquiring users. This while little quick apps like "Send Hotness" and "Kiss Me" explode and acquire millions of users.
Games, of course, is interesting because they might be one of the only categories that’s both deep and viral!
Monetization can support “garage entrepreneurs” but venture returns are still elusive
Another great discussion was around the monetization path for these apps and widgets running on social networks. I’ve written about many of these issues in 5 things that make your social network monetize like crap. Here are some datapoints:
- Plain ol’ AdSense and ad networks provide some developers with $100k+/month
- However, very few can support more than 4-5 guys working in a garage – there aren’t venture style returns ($50MM+/year) yet
- Currently, CPMs are in the $0.10-$0.20 range but need to get up to $1 range
And as a result, you have folks playing around with alternative monetization models:
- Virtual items and virtual currencies
- Co-registration, lead generation, CPA
- Many are looking forward to Facebook payment model for e-commerce
Overall, the issues that I outlined in my previous blog still hold true. The social network environments are not great for direct response revenue, and for the branding opportunities, the agencies are still uncomfortable with the user-generated content environments.
What’s next?
Next, I’ll be catching up on my e-mail and getting some real work done ;-)
Ask the readers: If you could drop 100M users onto any site, what would you build?

A great hypothetical question…
My cofounder Matt Rubens recently posed a great question to me over dinner:
Let’s say you had unlimited access to internet traffic, and could literally dump 100 million unique visitors in a single shot onto a site – what would you build?
I honestly don’t know the answer to this question, but here are a couple considerations:
- Any vertical site, be it pets or cars or even gaming, would ultimately lead to a huge % of the 100 million immediately bouncing and being lost – this might be OK, if the category is high value enough?
- Conversely, communication is probably the most horizontal application you could do, but it’s low monetization and not clear that you can go build in more depth after people think of you as a communication site
What do you guys think?
I would love any ideas or insights you guys have on this question!
Please comment to this post or send me an email at voodoo [at] gmail.
Reader question: Why answer questions?
A: There are probably 3 main drivers:
First, I like being helpful – I know there are problems that folks are facing which, if they had a short conversation, could help them skip months of turmoil. For some very specific topics, like building an ad network, or being an Entrepreneur-in-Residence, I can help with that. And I enjoy it!
Second, writing this blog is very much about honing my own thinking. So when folks ask questions that are challenging or expansive, it gives me an excuse to exercise my brain to come up with a reasonable response.
Third, when I get specific questions from people, it removes the abstraction of publishing to 2500 subscribers where I see the number, but don’t know anyone’s names or have any additional profile information.
Reader question: About college…
A: A lot of super smart people I went to college with had a very good idea of what they wanted to do right away, started working towards it, and are still on that path 10 years later. (Most of my Early Entrance Program classmates are now in med school, grad school, etc.)
… but not me :)
Instead, it took a while for me to learn that it was okay to go off the beaten path, and that I should go chase whatever I’m passionate about. However, even in Seattle, there aren’t many role models who can teach you the right way to manage that process. I would ultimately receive a lot of help from two Bills – Bill Ericson and Bill Gossman – who did teach me a lot about this.
In short, I wish that I would have had a more “strategic” view of how college fit into my life, as a tool rathe than as a monolithic step that I had to get past to get anything done.
(That said, stay in school kids!)
Reader Question: Are there new opportunities in social networking?
A: First, let’s talk definitions
I get variations of this question a lot, both online and offline. And everytime I’m asked, I tend to ask several followup questions, like:
- What do you mean by “social network”?
- What do you mean by “make it big?”
Let’s talk about the first issue, the meaning of a social network. One could define this as any site that has a standard set of pages like a profile page, a friend list, a newsfeed, a wall, and all the other mechanics. Another definition might be to do it more narrowly, like a set of mechanics and also the primary use case of communication. Yet another would be to define it as a site supportin the OpenSocial API.
It’s obvious, but the more narrowly you define the term, the harder it will be for a specific site to replicate its success. If you completely cloned Facebook today and released it to the wild, it would have a vastly different outcome than doing it 5 years ago.
Similarly, the concept of “making it big” is nebulous as well. For many entrepreneurs, making a company that throws off $5 million a year that supports a great lifestyle is an incredible outcome. Many indie Facebook developers and associated “lifestyle entrepreneurs” are primarily driven by that. For other entrepreneurs, they aspire for a billion dollar outcome.
My take on credible social network businesses
With all that said, I do think there are many opportunities for people to build sites with social networking backbones, and attract 10s of millions of users.
The reason is that there are simply too many people in the world interested in mega-niche topics, like:
- Fashion
- Knitting
- Board games
- NASCAR
- Kittens
- Photography
- Comic books
- Import cars
- etc.
And the same way that there are specific ecosystems of clubs, stores, student organizations, magazines, etc. that specifically cater to these niches, there will be websites that cater to these and will find some way of reaching millions of users.
I think where you run into problems as a business is when you are focused on a site that:
- Is contextless and primarily is used for communication
- Is reflective of your actual friend group (not new people)
- Is people-centric rather than centered on media, games, etc
Taking all of this out makes it so that your site not only supports the same use cases as Facebook and MySpace, but also has the same “feel.”
There are many permutions of this that can work well as a social network – it’s worth exploring more.
Trying out a new widget called Askablogr
For people who have this on RSS, please click to see my blog…
I’m trying out a new widget called Askablogr, which appears on the left pane. If you click on it, you can ask me a question, which I’ll then answer. (Maybe)
Try it out and let me know what you think!
I’m sick :( Also, going to Game Developers Conference for the week
Sorry for the slow blogging – I’ve been sick the last couple days.
This week, I’ll be at the Game Developers Conference held here in San Francisco. Couple predictions:
- The place will be SWARMING with VCs – there were only a few last year, but this year it’ll be over the top due to funding in the last 9-12 months
- Mobile games will continue to be dour, and the folks there will be jealous of all the new distribution opportunities afforded by Facebook/MySpace/etc.
- Internet people – that is, folks with backgrounds in Rails/SEO/SEM/widgets/etc – will in also be invading. These guys have never really built deep games before, but they sense an opportunity to build some simple content and use some new fangled techniques to distribute them
- "Club Penguin for X" has replaced "YouTube for X" as the new hotness
Also, here are a couple bloggers who write about games that you should read, if you’re not:
- Erik Bethke – GoPets
- Dan Cook – Microsoft
- Jeremy Liew – Lightspeed Venture Partners
- Daniel James – Three Rings
- Charles Hudson – Gaia
- Sean Ryan – Meez
- Nabeel Hyatt – Conduit Labs
I will be switching between the casual games summit and the worlds in motion summit in the first couple days, followed by attending the typical fanboy presentations on my favorite games. Should be fun!
From Seattle? Please introduce yourself…

I’m visiting Seattle later this month, week of Feb 25th
After almost a full year of not visiting the ol’ hometown, I’m finally visiting the area to see family and friends.
If you’re a reader of this blog, or if you have recommendations for folks I have to meet, please shoot me a note at voodoo[at]gmail, and include:
- Couple sentences about yourself and your background
- What are you working on?
I’m particularly interested in meeting entrepreneurial engineers who are building cool stuff.
Thanks!
Nasty ad on Facebook

A friend of mine sent this ad to me – on the top, you’ll see an ad that says:
, You Have 2 New Unread Messages
One Of Your Friends Has A Secret Crush On You. Find Out Who!
Combine this with the "CONTINUE" button next to it which matches the Facebook interface, and you get something pretty nasty. I assume that in the case where the ad network passes in your first name, they are able to personalize this message.
As I’ve said in the past, ad people come up with some very creative stuff – I still consider the geo-targeted Adult Friend Finder ads to be some of the most technologically advanced stuff online right now.
Diminishing returns on social media virality?
Question for the audience:
Response rates are falling on notifications, newsfeed items, etc. There’s a point at which it comes very very hard to be viral on top of Facebook anymore – this is starting to be true with e-mail virality, for example.
This roadblock will happen one day, but how long before we hit it? Months? One year? Years?
Folks with better visibility into Facebook viral stats would know better than I do…
BTW, I think this is a great reason for very app developer to be looking at OpenSocial right now, because it’s all green fields, and people who invest the time on things like language, cultural understanding, etc., will have a huge advantage in being able to generate the highest growth apps.
What’s happening with the top Facebook apps?
I collected the charts for the top Facebook apps and posted them below – overall, there seems to be a general decline. Note that this may NOT be a bad thing – perhaps developers are getting incented to create deeper and richer apps – more details below.
Anyway, looking at these charts: Why is this happening?
A couple thoughts:
- More apps means more competition (even for the top apps), which creates fragmentation – it become harder to keep any good thing going
- Changes to the Facebook viral channels are continually driving down the response rates, incenting developers to create stickier apps that can retain more active users
- Continual use/abuse of the Facebook viral channels are making users cynical, driving down response rates
- The top apps have hit the "carrying capacity" of the Facebook userbase, and have saturated the entire network – thus, the only option is for the usage to decay over time, since more viral growth isn’t an option
There’s probably multiple explanations here – note that for some of this, Facebook may be "guiding" the developers to create more meaningful applications via this "active users" metric, so even if the top apps are losing users, that’s OK.
Question for FB app developers: How do you avoid becoming a 3rd-tier Slide.com?

Strategic question for Facebook developers
During lunch today, an interesting question came up amongst a bunch of Facebook developers:
How do you avoid becoming a 3rd-tier Slide.com?
It seems like beyond the first couple players – Slide, RockYou, and others, there’s a huge drop-off for small teams who have raised <$1MM and trying to compete. Problem is, when you look at a company like Slide, they have 10-25X the number of people, 100X the funding, 100X the valuation, and 1000X+ the reach.
I’d be curious to hear how people are thinking about this?
My main thinking about this would be to pick some type of vertical – either by industry, demographic, media type, or something else that raises the bar for defensibility. It makes it much harder to be a "fast-follower." Anyone who is working on a purely horizontal communication basis will run straight into the Slide/Rockyou wall.
Any other ideas here?
The design of social spaces

Designing social spaces
Earlier today, I had a great conversation with Rashmi from Slideshare, where we dug into the design of social spaces – inspired by that, I wanted to write down a couple ideas that came up over coffee. Personally, I draw a lot of inspiration from offline social spaces, particularly malls, bars, cafes, stadiums, etc. There are places where these analogies hold, and places where they break down completely.
Here are some of the interesting design decisions for social spaces:
- What is the "unit" of your social space? (people/discussion/media/etc.)
- Is your social space open, closed, and somewhere in-between?
- How personal versus mainstream is the content on the site?
Let me emphasize that there are advantages and disadvantages to all of these different approaches – I’m sure there are many companies that are built using every permutation of this.
Anyway, to drill into each question in more detail…
What is the "unit" of your social space?
Every social site has a fundamental unit that’s tied together through social context. For MySpace and Facebook, that’s clearly people. For YouTube, Metacafe, and others, it’s video. For forums, it’s discussion-centric.
The easiest rule of thumb for understanding which unit dominates your social network: What is the core action your users are repeating over and over? If it’s navigating from video to video, that’s one thing, but navigating from person-to-person indicates another. For many sites, even when you are looking at a person’s profile, the most emphasized navigation element is to draw them back into a piece of media – that indicates that it’s media-centric rather than people centric.
An interesting example of this is Facebook photos – when you click into a person’s profile, you can then click through a whole bunch of photos. But ultimately a person "contains" a set of photos, and it’s not a "YouTube for photos" situation where I might be looking at a photo from Person A’s profile, and it lets me directly navigate to related photos from Person B’s profile. Instead, I always have to go up a layer from photos to the containing person, and then go to another person, then go down into more pictures. This emphasizes Facebook’s people-centric approach.
In my humble opinion, people-centric social networks tend towards communication (or pseudo-communication, like poking), which in turns tends to drive more stickiness. The reason is that when someone sends you a directed piece of communication, that’s the most urgent possible way to get you back to a site. Compare this to a piece of media that may or may not be directed to you – you might find it compelling, yet it doesn’t drive a huge sense of urgency.
Is your social space open, closed, and somewhere in-between?
Another key design decision has to do with whether or not your social space is open, closed, or somewhere in-between. If it’s open, then everyone can browse everyone else’s profile (or at least folks are visible). If it’s closed, you have to be invited to even see a single person, and vice-versa.
And there are examples like Facebook or Yahoo Groups which tend to be semi-open (or semi-closed, depending on how you look at water in cups). In those, you are able to browse people in your "network," but you can’t browse further than that.
By far, the most interesting issue here has to do with the process in which people self-identify with a web property or not. If it’s very open, then it makes it easy to say "oh these aren’t my people." The advantage of open, of course, is that you get some network effects as people join – you can reach a critical mass more easily (even if it’s in Turkey). On the flip side, if you are too closed, it can be harder to get started, but your site will seem more accommodating for a larger span of demographics.
How personal versus mainstream is the content on the site?
Photobucket, Flickr, and other photo sites ultimately hold a very different kind of content than YouTube. The reason is that the former has mostly "personal" content which is appealing only if you know the folks involved – sometimes this is combined with the term "long tail UGC." Compare this to YouTube, which has more mainstream content in the form of pirated media, mainstream studios releasing content, etc.
Of course, if you have personal content, it’s then important to either have a social graph of your own, or to sit on top of someone else’s. Otherwise, if you don’t provide an easy way for your friends to see your photos and vice versa, then the personal content is just sitting there. Of course, if you have both components – both personal content and the personal social graph, then you have a very sticky site.
Mainstream content is great, but lacks personal relevance. It doesn’t need a pre-existing social network to exist, yet it’s less relevant and not very urgent for users to consume the media. Of course in the case of YouTube, they exist on so many social graphs (MySpace/FB/Email/IM/WOM/etc.) that it doesn’t matter.
Couple attempts to classify successful consumer sites?
Here are a couple versions I’m thinking:
- YouTube: video-centric, open, mainstream+personal content
- MySpace: people-centric, open, mostly personal content (except for hot girl,s which is mainstream!)
- Facebook: people-centric, semi-closed, personal content
- SomethingAwful: discussion-centric, semi-closed, mainstream+personal content
- ICanHazCheezburger: cat-photo-centric, semi-closed, mainstream cat content :)
Am I missing anything from my framework?? I suspect there are a couple more axes I am leaving out.
Top keywords for how people find my blog
I always find the sources of traffic for my blog interesting – I thought I’d publish them here.
If you’re a blogger, you should go to your Google Analytics and hit Traffic Sources, then Keywords, and do an Export to Excel. Would love to see yours – please post it to your blog!
Couple observations about my list:
- Interesting that a lot of people are searching for me by name! Weird, although obviously there are probably tens or hundreds of thousands of "Andrew Chen" people out there, now and historically. Just at my college there were 5
- As to be expected, there’s a ton of folks who are searching about "Entrepreneur-in-residence" from my most recent gig
- Similarly, there’s a lot of folks who are interesting in advertising, viral marketing, and the typical digital media stuff I write about – hopefully they enjoy the content they see
- Also, interesting enough, there are a bunch of consumers who are looking for Diner Dash, or Facebook, or MS Paint, which are all consumer products I’ve mentioned in the past – those guys are probably very disappointed at what they find on this blog!
Here’s the first couple dozen of my list for 2007 to now:
- andrew chen
- entrepreneur in residence
- entrepreneur-in-residence
- andrew chen blog
- entrepreneur in residence""
- vertical ad networks
- viral loop
- futuristic play
- vertical ad network
- andrew chen""
- facebook dating
- andrewchen widget
- andrewchen reward schedule
- new diner games
- how to draw on ms paint
- sketchfu
- how to draw with ms paint
- andrewchen
- social monetization
- how to draw in ms paint
- club penguin viral
- game designer tutorial
- ideo method cards
- how to create a social network
- new diner dash
- first impressions ""andrewchen""
- google ecosystem
- futuristic
- ironic article
- widgets = ad networks
- andy chen
- game design tutorial
- uploading andrewchen
- 10 ways to ruthlessly acquire users
- 1 9 90
- 1-9-90 rule
- andrew chen mdv
- facebook monetization
- andrew chen viral loop
- facebook and dating
- site:andrewchen.typepad.com viral
