Author Archive
From analog dollars to digital pennies: The crisis in traditional media

How the core competencies of distribution-focused media companies are different than digital media websites
In this blog post, I’m going to discuss some random thoughts on about the evolution of media – I’ve recently been inspired by the conversations going on about the difficulties of transitioning from traditional media to the digital world. I thought I’d write down a couple notes on the media landscape and the idea that the skillsets of “pipes” companies – businesses that thrive on dominating distribution – are at a fundamental disadvantage relative to web businesses that promote interactive experiences.
Let’s get started with a rather famous person these days…
Miley Cyrus dominates because Disney dominates distribution (but for how long?)
For those that don’t follow the celebrity gossip blog as closely as I do, the girl above (who was born in 1992, which makes me feel old), is Miley Cyrus aka Hannah Montana. The Wikipedia article on her states:
Miley Ray Cyrus is an American child actress, singer, and songwriter. She is known for starring as Miley Stewart, “Hannah Montana” on the Disney Channel series Hannah Montana.
Cyrus became an overnight sensation after Hannah Montana debuted in March 2006.
Following the success of the show, in October 2006, a soundtrack CD was released in which she sang eight songs from the show. In December 2007, she was ranked #17 in the list of Forbes Top twenty earners under 25 with an annual earning of US$3.5 million.
What do Miley Cyrus, Britney Spears, Justin Timberlake, Christina Aguilera, Shia LaBeouf, Hillary Duff, Keri Russell, and the cast of High School Musical have in common? I mean, other than having ridiculous “pop” careers? Well, they were all, at some point, part of the Disney marketing machine that takes in normal kids and spits out billion dollar franchises.
And when you want to understand how this marketing machine works, you have to look at how all-encompassing the Walt Disney Company really is – here are the companies that all fall under the Disney umbrella:
ABC, ABC Family, ABC Kids, Walt Disney Distribution, Walt Disney Motion Pictures Group, Disney Channel, ESPN, Jetix, Walt Disney Studios, Walt Disney Parks and Resorts, Walt Disney Television Animation, Walt Disney Records, Walt Disney Pictures, Touchstone Pictures, Miramax Films, ABC Studios, Playhouse Disney, Disney Consumer Products, Pixar, Soapnet, Disney Interactive Studios, Muppets Holding Company, Disney Store, Toon Disney, New Horizon Interactive, Hollywood Records
And with 137,000 employees and >$35B in yearly revenue – well, if you want to make a little girl like Miley Cyrus famous, turns out you can!
Media consolidation and vertical integration go hand in hand
The point is, Disney and the many companies that would be considered its peers (Viacom, Fox, Sony, Vivendi, and the like) own the entire value chain from start to end in traditional media. In the “content is king” model, the focus is on producing content, but then owning the marketing, the distribution, and everything in between.
Does it surprise you that Time Warner both makes movies, and publications that promote movies, as well as a cable company that can distribute them on-demand? Or that one of the driving forces for Rupert Murdoch to buy MySpace was to use it to promote its movies, as discussed in this informative article in Hollywood Reporter? The saying, “content is king” means that when you’re the only game in town, you’re able to use your considerable cross-channel leverage to boost whatever you want and make it popular.
The problem is, where does that leave the customer?
If media companies are ultimately “pipes” companies – ones that primarily focus on distribution – what is their incentive to serve the consumer? I think that in the tech world, when we’ve seen this happen with Microsoft when it achieved superior distribution leverage relative to all its competitors. It creates perverse incentives to to try to squeeze whatever you can out of consumers, rather than innovating new products to serve them. And I’d argue that a lot of what we see in the entertainment industry – endless sequels, manufactured pop bands, child-actor-to-paparazzi-bait actresses – are all indicators that this is already happening. Why take content risk when you can just out-distribute and out-promote whatever you want?
Is the Mummy 3 the entertainment equivalent of Windows Vista? (I guess I shouldn’t be too harsh, after all the movie hasn’t released and I haven’t seen it yet – maybe it will be good!)
How vertical integration weakens with the internet
Of course, this vertical integration strategy starts to fall apart when you’re talking about digital content on the internet. The reason is that it’s hard to dominate it in the way that you can dominate offline distribution. It’s hard to be the only game in town. When the game is to own cable wiring, satellites, movie theaters, radio towers, and all that jazz, then the big guys have a natural advantage – scale is rewarded, and the bigger you are, the easier it is to own a bunch of infrastructure and operate it efficiently.
But on the internet:
- Anyone can set up a website
- It’s easy to copy, pirate, and otherwise separate your content from your distribution mechanisms
- With the advent of UGC, the engagement around media is also being captured off branded media sites as well
- Passionate vertical web communities are more engaged and can serve their specific audience better
- … and any entrepreneur with a couple hundred grand might end up with a website bigger than anything the old-school media companies can put together
So if you assume, at runrate, that any media you release will quickly (and virally) spread itself across the world, with or without your approval, and that people are likely to watch it at destinations you don’t own, then the traditional model starts to break. Things that you don’t expect to take off suddenly do, and the well-orchestrated launch of a “official” website for content might fall flat on its face. The problem is that the traditional source of power for media companies, the vertically integrated apparatus of content, marketing, and distribution becomes broken up into little pieces on the internet.
To this, I make the observation:
With the distribution efficiency of the internet, it becomes harder to control your consumers, and that’s a good thing :-)
So let’s talk about what companies might succeed in this new world…
The core competencies needed to succeed in digital media
If content becomes increasingly commoditized, and fragmented among many distribution vehicles, then what happens next? I’d argue that the new skills required to succeed in this era are NOT:
- Understanding how to best own/operate pipes, like cable systems, satellites, radio towers, etc
- Strong-arming partners and distribution to lock content into place
- Finding media synergies to cross-promote content and “make” hits
Instead, I’d argue that the new skillsets will be around serving the consumer, not pushing them. This means that media companies will need to grok:
- The economics of syndication and monetizing content off of “branded” media destinations
- Search, browse, and other aggregations of media content
- Personalization, recommendation, and social filtering
Will the traditional media companies make the leap? Or will they retreat into content, letting new players own the distribution layer? That seems to be what’s happening with YouTube, iTunes, and other strong players in the digital distribution world. The jump from controlling consumers versus serving them may be too big for these companies to make, but only time will tell.
Suggestions and comments welcome!
What are you really trying to measure?
I hugely enjoyed Fred Wilson’s blog this morning, where he discussed Three Statistics That Lie. In particular, he singles out:
– RSS subscriber numbers
– Facebook app install numbers
– Follower numbers on Twitter, Friendfeed, Tumblr, or some other social media service.
He points out the fact that RSS numbers show subscribers, but this number never goes down even though some people never actually read your blog – they just subscribed eons ago. Same with Facebook apps, and Twitter followers.
The point is, what are you really trying to measure?
In the Facebook case, the reason why “installs” feels like it’s not a great metric is that ultimately, value is generated by revenue, which is generated by ad impressions and CPMs, which are ultimately generated by active users. And active users obviously correlate with total installs, but it’s not a great correlation depending on how old the app is.
I would even break those active users down to users you can expect to retain, versus people you’re just dumping in and don’t expect to see again. (For example, RockYou’s Super Wall app recently had its viral channels taken away, and it showed that only 30% of the users were “retained” users versus people who come back because of notifications and such)
Anyway, numbers are numbers and they are meaningless if they’re measuring the wrong thing. So start with the business questions, which likely revolve around value generated as defined by an engaged audience that comes back and the revenue they throw off, and begin your model from there.
Trying out the new Amazon Recommendations widget
I recently read about Amazon’s new recommendation widget and I’d try it out. I think it’s another neat example of why even though Amazon’s business is almost all retail, they are really more of a technology company at heart.
In general I’ve found that the Google ads on my site absolutely don’t monetize at all – no surprise there :) Let’s see how these do.
Obama and McCain: How political marketing has evolved from offline to online

What?? A political post?
I’ve never blogged about politics before, and I’m not going to start :) This post is 100% about the evolution of marketing in the world of politics, not about any political positions. Anyway, I’m compelled by the fact that I’ve been encountering article after article about Obama’s mastery of the internet, and before that Howard Dean’s.
In particular, there was a great article in The Atlantic Monthly called The Amazing Money Machine with the subtitle “How Silicon Valley made Barack Obama this year’s hottest start-up.” In it, there are some great passages on how the Obama campaign has used technology to their advantage:
To understand how Obama’s war chest has grown so rapidly, it helps
to think of his Web site as an extension of the social-networking boom
that has consumed Silicon Valley over the past few years. The purpose
of social networking is to connect friends and share information, its
animating idea being that people will do this more readily and
comfortably when the information comes to them from a friend rather
than from a newspaper or expert or similarly distant authority they
don’t know and trust. The success of social-networking sites like
Facebook and MySpace and, later, professional networking sites like
LinkedIn all but ensured that someday the concept would find its way
into campaigning. A precursor, Meetup.com, helped supporters of Howard
Dean organize gatherings during the last Democratic primary season, but
compared with today’s sites, it was a blunt instrument.
And of course, you can’t forget Obama Girl, who now has 8.8 million views, or the Obama Facebook group which has over a million supporters now. Overall, pretty amazing stuff.
But as I mentioned above, this isn’t the first time that the Internet played a role in politics, since the Howard Dean supporters aggressively used services like Meetup and the MoveOn website to organize their efforts. Here’s an article from Wired magazine in 2004 describing the Howard Dean run.
Republicans and their direct mail expertise
Of course, back in 2004, another big story that played was the mastery the Republicans showed of direct marketing, particularly by Karl Rove who previously spent many years in that industry. In another article from The Atlantic, called Karl Rove in a Corner, there are some choice passages on how he thinks about targeting and direct marketing:
When Rove arrived in Alabama, in 1994, his clients were initially
puzzled as to why he was having them campaign in rural and less
populated parts of the state rather than the urban areas they were
accustomed to. It turned out that he had run an electoral regression
analysis on each of the state’s sixty-seven counties, and for
efficiency’s sake he put his four judicial candidates together on a bus
trip to the counties with the highest percentage of ticket-splitters.
“Karl got us focused on the fact that it was a matter of convincing
Democratic voters who were already conservative to vote for Republican
candidates,” Mark Montiel, a candidate on the trip, explains, “because
that was who best expressed their views.”… snip …
As with direct mail, Rove was skilled at reaching specific voter segments with television commercials, buying air time only during programs that he believed would attract the audience he was trying to reach. In his Alabama races he was known particularly to withhold advertising from The Oprah Winfrey Show and similar afternoon programming—”trimming a media buy,” as it is known in the trade. Bill Smith, who worked on a series of close races with Rove in Alabama, says, “There’s a real overlap in what he specialized in professionally and what you need to do in a tight race.” Whether he is seeking donors in a direct-mail fundraising campaign or manipulating a particular demographic sliver to win a close race, Rove’s professional goal has been strikingly consistent: to reach the right people.
There’s also another great article on the attempts for Mitt Romney, a Harvard Business School grad, to do this for his (ultimately failed) presidential campaign in the Post covered here. The point is, they were very smart about the process of collecting a vast database of data, using advanced marketing techniques like cluster analysis, machine-learning segmentation, regression analysis, etc. This is good stuff!
That said, in almost every article I’ve read about the subject, the focus of the Republicans seems emphasize direct mail – perhaps that’s a better vehicle for their demographic, or perhaps because that’s just the skillset they have developed over the last 10 years. However, there’s many studies about the efficiency of internet advertising versus offline, and politics is no exception – let’s take a deeper look at this:
Comparing direct mail to internet
There’s some interesting numbers comparing direct mail and internet-based donations in an article from the American Enterprise Institute, which states:
It is not just that he has built this
veritable army of contributors, most of whom will follow with him
through the fall campaign and beyond, if he is able to win the White
House. Having this base of small donors through a process that is
incredibly inexpensive to run, with fundraising costs that are 5 to 10
cents on the dollar (compared with 95 cents for direct mail), frees
Obama from the punishing, time-consuming burden of attending scores of
fundraisers and making thousands of phone calls to potential donors.
(Of course, Obama is not at the same time ignoring the $2,300 donors
and bundlers, which may create more flak for him through the rest of
the campaign. But he will certainly spend much less of his own time
courting donors than will McCain.)
(I bolded the sentence above). Wow! 5-10 cents on the dollar versus 95 cents for direct mail – what an amazing statistic. If you believe that, then it means you are almost 20X more efficient with internet marketing than direct mail, which is a huge number.
I’m not following the political campaigns that closely, but I’d be interested in a couple broad questions about how the approaches of the two parties are shaking out, from a macro-perspective:
- First off, are the Republicans majorly lagging in their ability to use the internet as a political vehicle?
- Similarly, do marketing channels like broadcast media and direct mail – which are “push” – fundamentally different than interactive media, like Facebook apps, YouTube UGC, etc.
- Can the same techniques that Rove used back in 2004 be re-applied to the internet? Is the DNA there, and it’s just a matter of time before the GOP cracks the nut for online marketing as well?
- For online marketing in politics, how quantitative are the approaches right now? Or is the offline-to-online opportunity so ripe that the qualitative stuff works without much thought?
Anyway, if anyone has any opinions or insight onto this, I’d be very interested to know. Comments and suggestions always welcome!
25 reasons users STOP using your product: An analysis of customer lifecycle
Churn from a customer lifecycle perspective
As much as I blog about viral marketing, it can’t be avoided that having healthy product retention is an equally (and incredibly) important part about having a successful product. Thus, in addition to talking about the issues around user acquisition, a similar discussion must be had around user churn.
In the customer lifecycle perspective, you look at the product from the perspective of a user that has a series of experiences starting from newbie and going into an advanced role. In addition to looking at the success cases, looking at the failure cases is informative too – you want to analyze your product for potential exit points and relate them to both quantitative and qualitative measures. More on the customer lifecycle concept here, by Josh Kopelman at First Round Capital.
Anyway, here’s a good example of this from the games industry: At the Austin Game Developers conference last year, there was a great presentation on why players leave their MMOGs from Damion Schubert (who also writes a mean blog here). There’s a very convenient writeup of his talk at Massively, which includes a great list. I’d encourage reading it in full. Obviously, the challenges that face more web-like products are very different, yet the same approach can be used.
Customer lifecycle within a social product
I imagine that many in the readership are working on social products – for any product in this space, you often have a number of fuzzy stages that a user can move through during their lifecycle. This may include stages like:
- First experience
- Soloing and single user value
- Encountering some friends(?)
- Hitting critical mass for social
- Becoming a site elder
Obviously every product is different, but the rough idea should hold for every social product out there. Early on, the initial experience is all about whether or not the user sees value in the product, and whether or not it “looks okay.” Then, oftentimes the users won’t have enough friends to make the site useful, in which case they fall back on a solo experience. Once they start hitting some other folks on the site, and making friends, then if done correctly, the site will hit critical mass and things will be sticky. And finally, in some products, some % of these users will turn into mods or admins or otherwise be elders within the product.
25 exit points
Now let’s look at all the different reasons why people might leave at any point – and obviously, the retention gets stickier and stickier in each stage, so perhaps reasons like “the site is too addictive!” become less effective :)
Anyway, there they are:
- First experience
- “I don’t get what this site is about”
- “This site is not for people like me”
- “The colors/design/icons look weird”
- “I already use X for that”
- “I don’t want to register”
- Soloing and single user value
- “I don’t have time to get involved in a site like this”
- “I’m lonely, not enough happens”
- “I forgot my password”
- “I don’t know how to talk or meet people”
- “I’ll just check on this account every couple months in case something happens”
- Encountering some friends(?)
- “People on this site are mean”
- “People I don’t know keep messaging me, WTF?”
- “I want my friends to use this, but none of them are sticking”
- “I’m getting too much mail from this site”
- “I only have 3 friends, this site is still boring”
- Hitting critical mass for social
- “This site takes up too much of my time”
- “Too many people are friending me that I only sorta know”
- “People are stalking me based on my pics and events!”
- “This Top Friends thing causes too much drama”
- “I’m getting flooded by e-mails for everything that anybody does”
- Becoming a site elder
- “The guys who run this site aren’t building feature X that we really need!”
- “The guys who run this site build feature Y that’s going to destroy this site!”
- “I’m doing a lot of work but I’m not getting anything for it”
- “I’m bored because there’s nothing left to do”
- “Newbies are fun to pick on :)” (wait, maybe that’s a benefit!)
Obviously, this is just a quick brainstorm of a list, but the point is, the reasons why people churn is often very different depending on their lifecycle. And some of the best things you can do for your product, in terms of retention, are things that are very positive for newbies, but might have side-effects elsewhere. You always want to balance each of these things off, depending on your product and business goals.
Am I missing anything else obvious? Comments and suggestions are always welcome!
Companies reading Futuristic Play – advertising, games, media, and more
One of the more unfortunate things about writing a blog focused on long-form essays that are not easily discussable is that you don’t get a ton of information about your audience just from comments and e-mail dialog. Through limited methods, I have some very rough visibility from what I can put together based on referrer logs, subscribed email addresses, and other sources.
Anyway, here’s a meta-blog post, in tradition with previous ones on top referrers, subscriber boosts from Scoble, and others, I wanted to share a short collection of the wonderful audience I’m very grateful to have reading this blog.
It’s pretty amazing to see how wide and interdisciplinary the audience is – there’s a ton of folks from super-consumery publishers/games, but also advertising and finance folks.
Here’s a selection of the companies that caught my eye:
Advertising and B2B:
- Aster Data Systems
- Medio Systems
- Revenue Science
- Tacoda
- Right Media
- Publicis Groupe
- … and a bunch of ad networks
Games and entertainment
- Electronic Arts
- Linden Lab
- NCSoft
- Sulake
- … and numerous startups like IMVU, Gaia, AreaE, and Weeworld
Media
- Joost
- Yahoo
- Virgin
- Slide
- MTV
- Hi5
- Tagged
- … and tons of Facebook developers and apps
Finance
- Lazard Freres
- Elevation Partners
- Mohr Davidow Ventures
- Blue Run Ventures
- Sierra Ventures
- Bessemer Venture Partners
Sorry if I’m missing anyone – I have a lot of empty referrer URLs, personal gmail/hotmail/yahoo addresses, and many other untraceable sources :)
Anyway, thanks to everyone for reading!
Poll: How do you launch a new product or service?
(If you’re viewing this in an RSS reader, you have to view the actual blog to see the poll below)
Craigslist to surpass eBay in 2009? Compete and Quantcast seem to think so…
At the Structure '08 conference, one of the eBay guys made the comment that scalability was a solved problem for them. A fellow conference goer observed:
airplanedan: must be nice to be ebay… James Barrese says they have scaling figured out and never have to worry about it again #structure08
This comment made me curious… Growth obviously makes scalability really hard, and how much is eBay growing anyway?? After pulling up a couple charges, in particular comparing things to Craigslist, you see some interesting results.
According to Compete, Craigslist has grown 76% in the last year while eBay has declined 11.6%:

If that pace continues – and your high schools stats warned you about the dangers of extrapolating- then Craigslist will pass eBay within the year. Wow! That would be big.
That means Craigslist will not only be the bane of all the old media newspapers, but also a former dotcom darling.
Here's the Quantcast graph for another datapoint:

More detailed analysis of social network value on Techcrunch
Michael Arrington posted an article this morning called Modeling the Real Market Value of Social Networks that uses a similar approach more data (and a better granularity of data) than the blog I wrote last week on the same topic. It's absolutely worth reading, so check it out.
(And Mike, thanks for the shoutout in the article!)
His blog concludes with the following chart, detailing valuations:

As you can see, MySpace, Facebook, Bebo, and Hi5 are all in the top 4, but interestingly enough, you also have companies like Ameblo.jp, Buzznet, Skyrock, Mixi.jp, and a bunch of other companies that have not quite entered the Web 2.0 discussion. Obviously it's looking at data like this which prompts those kinds of questions. In particular, thinking about the role of international traffic in social networks drives awareness of the fact it's harder to monetize.
After all, a pageview is not just a pageview – you have to think about where it's coming from, where it's being displayed, when it's being displayed relative to the user's session, who it's being sold by, and a myriad of other constraints that determines advertising CPMs.
MySpace versus Facebook: Analysis of both traffic and ad revenue, using Google Trends

(above, Facebook beating MySpace in Australia with the crossover at Oct 07)
Social networks have weaker network effects than previously speculated
- First off, MySpace is staying dominant in a few countries, like the US, Germany, Italy, Japan, etc
- Across the board, MySpace is the incumbent, and Facebook is coming from behind
- However, Facebook beaten MySpace on traffic in 14 countries over the last year
- In particular, June ’07 to Oct ’07 was particularly rough for MySpace, where 10 of the 14 countries were passed in this period
- In the markets where MySpace leads, you may consider them “mature” markets in the sense that both services have plateau’d in traffic – it’s not like MySpace growth is outpacing Facebook’s
Here’s the full table of data, so you don’t have to do the work:
| country | myspace leads | facebook leads | crossover date |
| Australia | X | Oct-07 | |
| Austria | X | ||
| Belgium | X | Nov-07 | |
| Brazil | X | ||
| Canada | X | ||
| China | X | May-07 | |
| Denmark | X | Oct-07 | |
| Finland | X | Sep-07 | |
| France | X | Nov-07 | |
| Germany | X | ||
| Hong Kong SAR China | X | ||
| India | X | ||
| Italy | X | ||
| Japan | X | ||
| Netherlands | X | Mar-08 | |
| Norway | X | ||
| Portugal | X | ||
| Singapore | X | Jun-07 | |
| South Korea | X | Sep-07 | |
| Spain | X | May-08 | |
| Sweden | X | Jul-07 | |
| Switzerland | X | Oct-07 | |
| Taiwan | X | Apr-07 | |
| United Kingdom | X | Jun-07 | |
| United States | X |
Overlaying advertising markets
Now, the second question is, how do advertising markets play into this? After all, it’s not enough to win on traffic, but you want to win on valuable traffic. For this discussion, I’ll borrow a diagram Jeremy Liew from Lightspeed wrote about regarding ad spend both domestically versus internationally, in 2007:

Here, you see that the US is by far the largest ad market, and is worth more than the rest of the world combined. I think that’s a key observation. Another observation can be made by combining this diagram with the traffic table above:
| country | myspace | crossover | 2007 ad spend (MM) | |
| United States | X | 19500 | ||
| United Kingdom | X | Jun-07 | 4727 | |
| Japan | X | 3397 | ||
| France | X | Nov-07 | 2548 | |
| China | X | May-07 | 1269 | |
| Germany | X | 1142 | ||
| Canada | X | 950 | ||
| South Korea | X | Sep-07 | 779 | |
| Brazil | X | 400 | ||
| India | X | 86 |
- MySpace leads in the major market (the US) but is losing ground overseas
- The overseas losses are material losses – not just random non-revenue countries
- The major losses all occurred in the mid/late 2007 timeframe
- Several markets are plateauing in traffic, meaning that the social network market is starting to mature – consider that MySpace+Facebook uniques, duplicated, is over 90M active users, which is a huge percentage of the online audience in the US
- How strong are the network effects of social sites, if incumbents can be displaced? Maybe it’s not so strong after all
Comments or suggestions welcome!
Free consulting on retention metrics* :)
*in exchange for data
Looking for usage/retention data
I am looking for some usage/retention data to analyze using some tools I've built in the last couple weeks. In particular, I'm interested in better understanding retention rates and segmentation analysis for web products. Unfortunately, I myself do not have a lot of this kind of data at this point, and would like to work on it.
So, I'm offering some consulting services around this for free, in exchange for a complete dataset that I'm hoping some of my readers may have. I won't guarantee anything, but I'll share whatever I come up with, and keep it completely confidential.
Data specs
This is the kind of information you'd need:
- list of user IDs and when the users were created
- list of user sessions with timestamps, or list of all user events with timestamps (which we can use to approximate sessions), or list of when each user uninstalled an app, etc.
- that's it!
If you're interested, shoot me an email at voodoo [at] gmail.
Thanks!
Andrew
Are you working on a product targeted at teens? 10% off YPulse Conference on July 14-15

Thinking about Generation Y, not just tech
One of my favorite blogs, YPulse, covers a great range of marketing, tech, and lifestyle issues around the teen demographic. The reason why I'm a fan is because they aren't just tech focused, but consider the research from A-Z on this demographic. Obviously it's great for people who are:
- Working on social gaming or virtual worlds
- Building out social networking sites based around games, media, or otherwise
- Similarly, anyone who's doing Facebook or OpenSocial apps, to figure out what makes this demographic tick
Anyway, they are having a conference on July 14-15 in San Francisco, and they let me share a discount code. Here's the registration info:
REGISTER HERE
10% discount code: FUTURISTIC1
You can view the agenda here. They are having a screening of a documentary covering the demographic as well as a Q&A with a panel of teenagers at the end of the night also, which should be fun.
Sessions
A couple sessions I'm interested in – see you guys there:
Brand Engagement in Virtual Worlds for Youth
* Creating virtual world experiences residents will love
* How do you measure ROI in virtual worlds?
* Connecting virtual engagement with real world engagement
Panelists:
Lauren Bigelow, General Manager, WeeWorld
Teemu Huuhtanen, President, North America, Sulake (Habbo)
Craig Sherman, CEO, GaiaOnline
Michael Wilson, CEO, There.com
Are Girls The New Geeks?
* Understanding how girls and boys use the web
* What works in reaching girls vs. boys
* Girls are creating content, but what are they learning?
Panelists:
Nancy Gruver, Publisher, New Moon Girl Media
Allison Keiley, Online Content and Community Manager, Girls, Inc.
Ashley Qualls, CEO, WhateverLife
Holly Rotman, Senior Web Editor, eCRUSH/eSPIN; Writer, "Advice Girl" column, eCRUSH.com, Hearst Magazines
Where are all the video startups? Maybe Content=King, online and offline
I ran across this interesting diagram from comScore on the top video properties online:
|
Top U.S. Online Video Properties* by Unique Viewers |
||
|
Property |
Unique Viewers (000) |
Average Videos per Viewer |
|
Total Internet |
134,471 |
81.6 |
|
Google Sites |
83,720 |
49.7 |
|
Fox Interactive Media |
52,046 |
10.7 |
|
Yahoo! Sites |
37,323 |
9.4 |
|
Microsoft Sites |
29,908 |
9.0 |
|
Time Warner – Excl. AOL |
20,627 |
6.7 |
|
Viacom Digital |
19,367 |
10.3 |
|
AOL LLC |
19,115 |
5.0 |
|
Disney Online |
10,805 |
9.1 |
|
ESPN |
9,026 |
9.2 |
|
CBS Corporation |
7,993 |
7.1 |
My first thought was… why are there no startups on this list? YouTube is the closest, and obviously they are dominating, but how about all the other folks?
A theory on this is that most startups have focused on aggregating long-tail video online, and displaying it as a "content site" similar to YouTube. That is, one would focus on just aggregating and displaying content, rather than building too much complexity on top of it.
Compare this strategy to the one employed by many of the top media companies listed above – they are taking their wells of proprietary content and posting it online, and mainstream content is able to drive traffic with or without surrounding featureset. If you check out ABC.com or many of the major network sites, they don't do anything fancy – just post the content in Flash and off you go. It really makes you believe that content is king, both online and offline.
Social gaming design – Bartle types versus Web 2.0 participation pyramid
By spending time in the “social gaming” space, it’s interesting to see the intersection of approaches from both the consumer internet folks versus the traditional game folks. In addition to business models (ads versus subs/virtual goods) or product emphasis (functionality versus storytelling/characters/etc) or other topics, I’m particularly fascinated by the difference in how they think about their players/users and their activities.
Let’s look at the two approaches – both the “Web 2.0” view as well as the games perspective. The former is represented by a pyramid, and the other is a 2-axis landscape.
A while back, Bradley Horowitz (then at Yahoo) wrote an article on a “pyramid of value creation” classifying Creators, Synthesizers, and Consumers. He uses the following diagram and writes – bold formatting is mine:
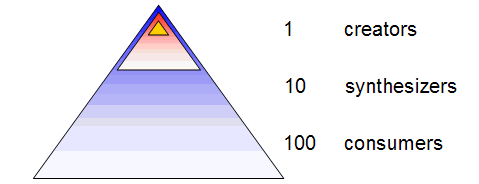
The levels in the pyramid represent phases of value creation. As an example take Yahoo! Groups.
- 1% of the user population might start a group (or a thread within a group)
- 10% of the user population might participate actively, and actually author content whether starting a thread or responding to a thread-in-progress
- 100% of the user population benefits from the activities of the above groups (lurkers)
There are a couple of interesting points worth noting. The first is that we don’t need to convert 100% of the audience into “active” participants to have a thriving product that benefits tens of millions of users. In fact, there are many reasons why you wouldn’t want to do this. The hurdles that users cross as they transition from lurkers to synthesizers to creators are also filters that can eliminate noise from signal. Another point is that the levels of the pyramid are containing – the creators are also consumers.
The use of a pyramid reinforces some subtleties which I bold above:
- There’s a hierarchical view of how users are perceived, with a linear path
- Creators are generally seen as “higher value” than the less involved users
- There’s an effort to “convert” lower value users into creators
Another good discussion and example of the pyramid point of view is here at Jeremiah Owyang, in an article called See Actual % of “Community Pyramids” with Technographic Data.
Let’s return to the pyramid a bit later in this blog.
The Games point of view
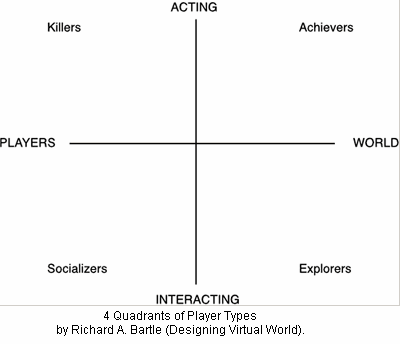
The four things that people typically enjoyed personally about MUDs
were:i) Achievement within the game context.
Players give themselves game-related goals, and vigorously set out to achieve them. This usually means accumulating and disposing of large quantities of high-value treasure, or cutting a swathe through hordes of mobiles (ie. monsters built in to the virtual world).ii) Exploration of the game.
Players try to find out as much as they can about the virtual world. Although initially this means mapping its topology (ie. exploring the MUD’s breadth), later it advances to experimentation with its physics (ie. exploring the MUD’s depth).iii) Socialising with others.
Players use the game’s communicative facilities, and apply the role-playing that these engender, as a context in which to converse (and otherwise interact) with their fellow players.iv) Imposition upon others.
Players use the tools provided by the game to cause distress to (or, in rare circumstances, to help) other players. Where permitted, this usually involves acquiring some weapon and applying it enthusiastically to the persona of another player in the game world.
Later on in the article, he also touches on the dynamics between each one of these Bartle types, and how they interact to create the community that makes up a game. He also discusses methods of increasing or decreasing the prevalence of certain types, since oftentimes having too many or too little of a particular type can cause imbalance to the community.
A couple observations on this:
- The 4 types are primarily treated as peers to each other
- By presenting it as a 2×2 landscape, it also expresses the idea that a player might be in one type yet flirt with another
- Yet, the diagonals are problematic, since it’s hard to express an Achiever who is also a Socializer
Let’s compare the two viewpoints now.
Comparing the two perspectives
It’s clear that there are clear differences between the two views. While one more closely resembles a linear, hierarchical view, the other represents a flatter, multi-variable view.
In general, I think the two views are in conflict with each other due to the emphasis on user-generated content versus company-created content. In a pure UGC web 2.0 site, you need the content creators otherwise there’s nothing to do for anyone else. Take a site like Digg or Facebook, and if it’s just you on the site, it’s not so interesting. Compare this perspective to the games world, which has long built gradual “solo” experiences that then open into social experiences.
In almost any MMO, you can still play it for a while before you have to start thinking about other people. There’s a long “single user” experience that makes the game fun and entertaining, even if you’re the only person logged on. For socializers, you can talk to NPCs and get your kicks that way. For achievers, you can fight monsters and level up your character. For explorers, you can still check out the world and try out all sorts of different things. By investing in a content experience up-front, there’s less of a reliance on content creators to make it all work.
In general, comparisons like this make me think more about the user/player lifecycle of any product – how do you bootstrap the initial experience and make that fun? How do you pivot the user into trying other things, in particular with real live people? How do you build the critical mass to make social experiences interesting? As always, there’s a lot for Web folks (like me) to learn about from the games people.
Comments and suggestions always welcome!
Social Gaming Summit: Recap and observations

For every conference event summary that's posted, there's already an existing one that's earlier, more comprehensive, and better written ;-)
In this case, Justin Smith and Mashable have already posted some partial writeups here and here. Instead, I'll just focus on a couple observations shared during the panel discussions which I found interesting.
A very compelling point made today by the IMVU CEO Cary Rosenzweig was around the process of designing IMVU from the ground up, rather than their previous project There.com. He said that when the IMVU originally constructed There.com, the problem was that they created a ton of "space" without the social activity to make it dense enough and interesting enough. It was too easy for users to end up wandering around the environment without interacting with each other enough. This description reminded me of the problems that Half Life faced early on, described here, where the levels weren't fun and had to be reconstituted to be as "dense" experientially as possible, to make it interesting.
Another comment I liked was when Daniel James from Three Rings pointed out that in many cases, virtual worlds can be much tougher to build than traditional "games." The reason is that for his previous game, Puzzle Pirates, which revolves around a pirate theme, there is clear context. You know that pirates seek treasure, fight other pirates (and the British Navy), steer ships, say "ahoy" and "AARRR," and other ideas that fit into the mythology. This ultimately creates an internal set of motivations where the players sorta know what to do!
Social Gaming Summit tomorrow – see you guys there!
Charles Hudson of Gaia invited me to attend the Social Gaming Summit tomorrow in San Francisco. Should be a lot of fun! I'll write a quick blog covering the conference, to sum it all up.
10:00am – What Makes Games Fun?
We all like to have fun, right? What is it about games that makes them so fun? Is it gameplay? Social interaction? Achievements and accomplishments? Our panel of thought leaders will share their perspectives on what it takes to build a fun game and why building fun into games is more difficult than it looks.
» Erik Bethke – CEO, GoPets
» Dr. Ian Bogost – Founding Partner, Persuasive Games
» Nicole Lazzaro – President, XEODesign, Inc.
» John Welch – Co-Founder, President & CEO, PlayFirst
» Jeremy Liew – Managing Director, Lightspeed Venture Partners (moderator)
11:00am – Casual MMOs and Immersive Worlds
Many so-called “casual MMOs” and immersive worlds are casual only in the sense that the point of the game is not to bash gruesome looking monsters or the game isn’t set in a sci-fi fantasy world. The engagement story around existing and upcoming casual MMOs is real and very compelling. This panel will discuss what it takes to build a successful casual MMO that users love to play.
» Min Kim – Vice President of Marketing, Nexon America
» Patrick Ford, VP Marketing and Community Development, K2 Networks
» Kyra Reppen – SVP and GM, NeoPets
» Craig Sherman – CEO, Gaia Online
» Joey Seiler – Editor, Virtual Worlds News (moderator)
1:30pm – Asynchronous Games on Social Networks
There are a lot of interesting asynchronous activities happening on social networks. Some of them are traditional games, others are games in disguise. Join us and hear from some of the leading voices in this space share their views on how to build great gameplay characteristics into social networking applications and what opportunities exist for gameplay to take advantage of the social graph.
» Siqi Chen – Founder, Serious Business (Friends for Sale)
» Blake Commagere – Founder and VP Engineering, Mogad
» Shervin Pishevar – CEO, Social Gaming Network
» Mike Sego – Developer, (fluff)Friends
» Andrew Chung – Principal, Lightspeed Venture Partners (moderator)
2:30pm – User Generated Games in Social Networks and Virtual Worlds
Games are one of the most popular activities on social networks and virtual worlds. Increasingly, users are taking it upon themselves to create games and entertainment of their own within the context of existing online environments. Curious as to what’s driving this behavior? This is the panel for you.
» Daniel James – CEO, Three Rings
» Jeremy Monroe – Director of Business Development, Sports & Entertainment, North America, Sulake Inc.
» Ted Rheingold – Founder, Dogster and Catster
» Cary Rosenzweig – President and CEO, IMVU
» Dean Takahashi – Writer, Venture Beat (moderator)
4:00pm – Building Communities and Social Interaction In and Around Games
Social networking and games go hand in hand. Whether it’s taking advantage of the relationship data in social networks to build novel gameplay or building community among people who play games, game developers are discovering clever ways to build real communities around the games they’re developing. Hear from our panel of thought leaders about what it takes to successfully integrate community and social interaction into the next generation of games.
» Jim Greer – CEO, Kongregate
» Amy Jo Kim – CEO, Shufflebrain
» Mark Pincus – Founder and CEO, Zynga Game Network
» Dave Williams – SVP, Shockwave, AddictingGames
» Brandon Sheffield – Gamasutra (moderator)
5:00pm – Monetization and Business Models for Social Games
There are a handful of viable (proven) business models for social games. How should game developers go about choosing the best business model for their games? Our panel of experts will share their thoughts on the various business models and how to think through the right one for a given game.
» Jameson Hsu – Co-Founder and CEO, Mochi Media
» Matt Mihaly – CEO and Creative Director, Sparkplay Media
» Mattias Miksche – CEO, Stardoll
» David Perry – CCO, Acclaim
» Ravi Mhatre – Managing Director, Lightspeed Venture Partners (moderator)
Dear readers, need a quick favor!
Hi all, I'm looking for recommendations/intros to find a great frontend engineer for a consumer internet project I'm working on. Ideally, would be located in the Bay Area or willing to relocate.
5 steps towards building a metrics-driven business

Don't ask me about viral marketing, ask me about metrics
Given my history blogging about viral marketing, I'm occasionally approached by folks who ask me, "For product X, how would you promote it and make it viral?" I think there's an expectation that there's a playbook which you can directly apply to every situation.
- A/B testing your upload page to make people more likely to upload
- Delivering a ton of email notifications prompting users to upload
- Using switch-and-bait tactics like information-hiding, creating false incentives, etc.
- Creating a gimmicky points system to upload photos
In many cases, I feel like many Facebook apps are trying to solve their problems by enacting the solutions as above. I think the quantitative side lends itself well to the above approaches, yet you rapidly hit diminishing returns.
- Repositioning the product for a higher resonating value proposition
- Going after a different kind of audience to target their needs
- Recalibrating the "core mechanic" of the product to make uploading photos a natural part of using the product (like HotOrNot, for example)
Finally, it's important to execute your scientific approach with proper test and control methods:
A/B testing is a method of advertising testing by which a baseline control sample is compared to a variety of single-variable test samples. A classic direct mail tactic, this method has been recently adopted within the interactive space to test tactics such as banner ads, emails and landing pages.
Employers of this A/B testing method will distribute multiple samples of a test, including the control, to see which single variable is most effective in increasing a response rate or other desired outcome. The test, in order to be effective, must reach an audience of statistical significance.
This method is different than multivariate testing which applies statistical modeling which allows a tester to try multiple variables within the samples distributed. (from Wikipedia)
Summary
- Create clear, measurable goals
- Make an uber-model that breaks down key variables
- Collect both quantitative and qualitative data
- Generate hypotheses around key variables and variable combinations
- Execute test and control methods, and don't confuse correlation with causality!
For those who are dipping their toes in the water, I hope this helps!
Users, customers, or audience – what do you call the people that visit your site?
5 second personality test
This is a just-for-fun post on the way that language changes our perspective on design. I've been thinking a lot about these nuances in the way that it creates hidden assumptions on business models, how we treat our partners, our users/customers/audience, and other folks in the industry. As a result, I've come up with a one question personality test ;) Here's the question below:
What do you call the people who are on your site?
- Users
- Customers
- Audience
Have your answer?
Read below for some quick thoughts on what your answer could mean.
Audience
Folks that use the word "audience" are likely to have an advertising and monetization perspective. Ultimately, companies with an ad perspective see the audience they are building into an asset to be sold to their "real" customers, the advertisers. And so I hear phrases like X wants to "target this audience" or that they're "aggregating the Y audience" or similar wordings.
As I wrote in Your Web 2.0 startup is actually a B2B in disguise, the process of generating all those millions of pageviews is just step #1, and step #2 is to actually sell them to the advertisers who want to target this audience. That's absolutely a valid perspective.
Customers
The view of the people on your site as "customers" has the strong connotation that direct monetization is occurring, and that usually happens on ecommerce properties. I think this implies both the highest value and best treatment of the folks visiting your site.
Interestingly enough, business like social gaming sites would be wise to use this type of terminology when they depend on virtual goods models. Social gaming properties are not much unlike ecommerce sites, and it would be wise to have the same focus on merchandising, having attractive shops, cross-selling and up-selling, as well as treating your customers like they will hand you money.
Users
At the heart of "users" is the idea of using a product, or utility, or other functionality-focused usage. At least in my world, this is the most common terminology I hear. On the plus side, it creates plenty of opportunties for discussion around featuresets and product-oriented business strategies. However, on the downside, it doesn't explicitly acknowledge the nature of the advertising business as "audience" does, nor the imply the treatment that calling them customers would.
For my projects, I am particularly interested in virtual goods models for monetization, and as a result, it seems wise to reserve the word "customer" to refer to the people we attract.
Any other labels I'm missing? Comments and suggestions welcome.
Data portability: Is the social network data you’re hoarding treasure or trash?
I recently wrote a guest blog yesterday at InsideFacebook.com, and wanted to republish it here as well.

Data portability: What's the value of your social network data?
This blog post will be focused on the business-perspective of how a
company operating one of these social networks might think about their
data, particularly in regards to advertising monetization.
There's been a lot of discussion on the data portability issue in one form or the other. The consumer perspective on the data portability issue on the consumer side has been well-covered, and is well represented by Robert Scoble, Marc Canter, Gillmor Gang, and others. This is a big topic, especially when you've added as many friends
to Facebook as our Doonsberry friends have, in the above comic.
Business reasons to resist portability
When a company has aggregated a critical mass of audience and data, it's clear that data is worth something, but unclear how much. In particular, one might be resistant to data portability for a number of reasons, including:
- If the data can be monetized for through advertising means, then a company might want to have proprietary access to that data
- If a competitor can easily import user data, it makes it easier to switch services
- If a user can too-easily share their data with external services, it may create privacy and security issues
- … and others
There are many other reasons why businesses are reluctant to jump full bore into releasing control of the data, some great for consumers, some neutral, and some completely unaligned with their users. It's my opinion that, like the way Windows has evolved, you want to provide access but need to make it very clear what they are getting themselves into.
The reason why spyware has turned into such a huge industry was that for many years, it was far too easy to install any executable off the internet – and the Operating System gave poor warning on what users were trying to do. There are things you want to do to make sure you're not destroying an entire ecosystem, while still supporting the goals of your users.
My particular interest in this question mostly has to do with the value
of the data, particularly from an advertising standpoint – the first
bullet above.
The monetization of user data
The question is, if companies are busy hoarding all this user data – what is it really worth? How do you evaluate its value? And how does it fit into the context of the overall advertising market?
To outline the answers to this question, I'll cover a couple specific topics:
- Ad network business models
- Interest versus intent
- Data to traffic overlap
Then I'll conclude with a short discussion on the future of social network data.
Ad network business models
The market for user data is very early. Only in
the last few years have companies emerged like Revenue Science, Tacoda,
Blue Lithium, and other companies you see on this list.
Note, of course, that I was previously employed by Revenue Science and
worked on their direct response ad network (in addition to other roles).
But to step back: For newbies to the advertising world, it's important to note that there are many many ad networks out there besides Google AdSense. For example, Blue Lithium, Valueclick, ContextWeb, Advertising.com, etc are all ad networks that fundamentally do the same thing:
Buy ad space at a lower price, then resell it for a higher price
Quite simply, it's arbitrage. So they sign up publishers, get them to stick ad code on their pages, and then fill the space with banner ads, Punch-the-monkey flash games, etc. The bigger the delta between what the buy it for and what they sell it for, the better their profit margins.
The problem is, there's like 300 ad networks out there, and it's getting more competitive every day. So like a Wall Street bank, these ad networks have to get smarter (and bigger!). They allow advertisers to target on context, geography, time, demographics, and many other factors. They support Flash ads, text ads, video ads, banner ads, all in many different sizes.
In all the targeting, they become huge consumers of data. To competitively identify low-value ad inventory and buy it on the cheap, you need to have more data than:
- the publisher you're buying it from
- the 299 ad networks who are also looking for the low-value inventory
If you have less data than either, then the ad inventory price will get bid up, and all of a sudden it'll be hard to get the volume of traffic you want. And thus, it makes sense to voraciously gather and utilize all the data you can, across many different areas. In particular, "user data" is interesting – if you can tell when someone in the market for a car, ad impressions against that user are suddenly very valuable.
Question is: What kind of data is valuable? And what kind is not?
Interest versus Intent
The first step to understanding the value of data is to look at the marketing funnel below:

You can consider the top part as consumer interest whereas the bottom part is consumer intent.
A user moves through a long funnel before coming into market and exhibiting buying signals (aka Intent). And there are a lot more people at the top, who are sorta kinda maybe in the market for a car (but maybe don't even know that they are) versus the folks at the bottom of the funnel who are ready to get their car loan processed and drive out to dealerships the next weekend.
When you are the bottom of the funnel, you are part of a select group, and because you are very close to taking action, it's easy to value you as a user. Here's how a car dealership might figure that out:
- The dealership closes roughly 1% of anyone coming through as a "lead"
- They make on average $2000 per car they sell
- So they are willing to buy a lead for $20
- Then build in some margin, and they're willing to spend $10 on a lead
(Note: these are made up numbers)
The problem here, however, is that there are only so many people ready to buy at one time. So typically, all this inventory gets sold out, and then you have to move upstream to buy more users. In particular, there's often a big concern that a product can get left out of the "consideration set" if it's not branded well. That is, even if you're buying all the Ford dealership leads as you can, if you can't position your gas guzzling SUV for the eco-conscious set, they never get the chance to filter to the bottom.
When you're at the top of the funnel, it's hard to value the ROI from advertising to those users. The focus there is to just be in the game and inside the "consideration set," as I mentioned. So the targeting there isn't typically focused on in-market status, but rather on more qualitative things like:
- demographics
- psychographics
- desirable editorial areas (to complement the values of your brand)
- really cool ad creative
- etc.
Anyway, it's not as quantitative, and the distance between the brand side and revenue is often larger than folks want it to be. But it works, even through the following classic advertising quote applies:
"Half the money I spend on advertising is wasted; the trouble is I don't know which half"
— John Wanamaker
As a result, it may not surprise you that data around in-market behaviors (aka Intent) are worth a LOT more than the more watered down stuff (aka Interest), particularly because you can prove to advertisers that the former will make them money.
For search engines, the ultimate collector of consumer intent, you can get 1000X+ times the monetization levels that you'd get from social networks. Social networks, being communication-oriented, have very little intent relative to other sites on the internet. This doesn't mean the social network data is worthless, but it's definitely hard to use it to monetize.
Where are other places you can find intent?
- Comparison shopping sites
- Product reviews
- Loan calculators
- Shopping sites
- Search engine marketing landing pages
- etc.
Think of any service you might go to in order to make a transaction, or prior to making a transaction. The more of that data you have, the better off you are.
On the flip side, this data is scarce. The bottom of the funnel doesn't have many people, and because people aren't typically shopping forever on a product, it means the data is perishable.
Data to traffic overlap
Once you have the data, you have to figure out how to use it to buy-low and sell-high. One of the big questions revolves around when/where your data is applicable – and this problem is sometimes referred to as "overlap."
Let's say that you collect data about a bunch of unique users on your site, and all those users are very valuable. Then you want to find those same users on some other site, which has cheapo inventory. The plan is that if you can buy that inventory for cheap, but you can figure out the good stuff in there, then you can buy just the good stuff. Sounds great right?
Problem is, what's the overlap of users between your site and this publisher's? If it's small, then you might not be able to write a big check to justify the expense of doing the transaction. If you have 100k users and then you're finding some % of that on some other site, then that's not so exciting. So you really need to aggregate a ton of data to make this transaction work. And ideally, you are able to use your own data, but also use the data of other similar ocmpanies – this allows for more opportunities to bring in new users, rather than just recycling the current set of users you already have.
This issue of insufficient overlap has been alleviated somewhat recently. Since the mid 00s, there's been a number of ad networks that allow you to buy advertising by-the-cookie. Right Media, in particular, leads in these types of transactions. But Valueclick, Ad.com, etc all can provide similar arrangements as well. So given that these ad networks have already pre-aggregated a huge amount of inventory (several hundred billion pageviews per month), you can get reasonable scale on your data even if you don't have too much data. The downside to this, of course, is that it introduces yet another middleman into the mix, and since they know you are buying by-the-cookie, it's easy for them to charge you a little extra. Doh.
Conclusion
So to summarize the article above:
- One potential issue that makes social networks resist data portability is the monetizability of the data
- Not all user data is created equal, there's interest versus intent
- Social networks generally produce lots of low-value interest data, which has weak ROI attached to it
- Search engines, review sites, comparison shopping, etc all produce high-value intent data
- Even if you have the data, you have to worry about whether or not you have enough of it to matter – although ad networks and exchanges have started to alleviate that
Questions and comments welcome!
Social gaming and MMOGs: Quick link roundup
A friend of mine recently asked me for a list of blogs, books, and other resources on game design, social gaming, virtual goods, etc. I wrote up a quick e-mail, and thought I’d publish it here as well.
If anyone has interesting stuff to add, please shoot me a note at voodoo [at] gmail!
I have not found much on the metrics of the games industry, particularly on the virtual economies side. That’s definitely one area I’d like to learn more about…
MMOG and virtual world blogs:
- Virtual World News
- Massively
- Terra Nova
- Virtual Economics
- Virtual Economy
- Free to Play
- PlayOn from PARC
- Worlds in Motion
- Jeremy Liew (Lightspeed)
- Dan Cook (Seattle game designer)
- Daniel James (CEO of Three Rings – Puzzle Pirates & Whirled)
- Sean Ryan (CEO of Meez)
- Nabeel Hyatt (CEO of Conduit Labs)
- Erik Bethke (CEO of GoPets)
- Nick Yee (Stanford researcher on virtual worlds)
- Justin Smith (Inside Social Games)
- Damion Schubert (MMOG designer)
- Designing Virtual Worlds (New Riders Games)
- Play Money: Or, How I Quit My Day Job and Made Millions Trading Virtual Loot
- Massively Multiplayer Game Development (Game Development Series)
- Game Design Workshop: Designing, Prototyping, and Playtesting Games (Gama Network Series) (Gama Network Series)
UPDATE: added a couple new links. There’s more on Mike Gowen’s blog here.
User retention: Why depending on notification-driven retention sucks

- They love your site so much that they come back themselves (direct-navigation)
- They see or get a link from a friend or a source while they are browsing (reacquisition)
- You send them a notification, like a friend-add, a newsletter, a list of top videos, or similar
The case where the user navigates to your domain to come back is great. It means that you've built a brand that people can recall from their memories, and they like it enough that they will automatically come back. In general, this seems like the most desirable scenario.
- Good friend sends you a private message
- Friend writes on your profile
- Acquaintance writes on your profile
- Friend sends you a friend request
… versus less desirable messaging, which lacks personal context and comes from the company, not a friend or :
- "Come try out new feature X!"
- "Check out this week's top videos!"
- "You should update your photo!"
- Total stranger sends you a friend request
In the cases where you are getting notifications from just the site, it's far more likely users will think of it as spam, which is obviously a negative. The more personal information that is in the notifications, and the more personally relevant that information is, the better.
- Initial active users = 1000
- % that will create useful news = 10%
- % that will click through on the notification: 5%
- The idea is that you have 1000 users, of which 10% will create useful news
- That means 100 people will create news
- As long as there's at least 1 piece of news, that news can be republished to 1000 people as 1000 notifications (Note that in a more sophisticated model, the more news items, the better the clickthrough rates, and the less, the smaller the CTR)
- Once you have 1000 notifications out there, then there's 50 people that click through
- Of those 50 people, they produce 5 pieces of news
- That 5 pieces of news is then republished again to the 1000 people
- Then the secondary cycle repeats again
Basically, there's a quick collapse from 1000 active users down to 50 active users. If you made the model more complex, and added a CTR that goes down depending on how much news there is, or adding deliverability issues from people getting too much e-mail, then you could see this spiraling down to 0 actives.
- Build features that support high-quality single-user experiences
- Make it easy to create content on the site, and reward users that do
- Create differentiated experiences that users can weave into their daily routine
- Be as sticky as possible – this is a place where software clients are great, but websites are hard
What’s the value of a user on your site? Why it’s hard to calculate lifetime value for social network audiences

Who is this, and where can I find more pics??
For those of you who aren’t familiar, the photo above is of Christine Dolce, aka Forbidden, who is a famous MySpace celebrity (and will surely get her chance to star in a VH1 reality TV show). I can hear a rush of clicks googling her for pictures, so I’ll just provide you the link to her MySpace profile here. Let’s get back to Forbidden in a second, since she fits into a larger discussion.
LTV and the goal of infinite segmentation
The core of many marketing programs is segmentation – you take your core audience, identify differences between their motivations, spending patterns, and behaviors, and tailor your messaging to hit that audience. The better defined your segments are, and the more granular they are, the more opportunities you have to personalize your message when you reach out to them.
One way to do this segmentation is to look at "Lifetime Value" (LTV). Calculating lifetime value (LTV) of your customers is a great way to understand how they fit into the core of your business. Typically, your best customers will represent a significant amount of revenue, and you want to make sure they’re happy. Having a granular LTV calculation where you plug in a user’s historical data allows you to come up with infinite segmentation in terms of how you want to differentiate the experience high-value customers get versus low-value ones.
LTV for retail sites versus social sites
For retail sites, the calculation of LTV is pretty clear. In plain English, you might define it as:
The stream of all previous and future profits that a user generates from their purchases
So for a given user, you’d add up all their previous transactions and then add that to whatever model you’ve created about their likely future transactions. Part of what makes this work is that:
- Transactions in a retail setting are unambiguous
- Each individual makes an isolated impact on the system, in the form of a transaction
- Retail buying has a long established history of data, both online and offline
Now let’s look at social properties, particularly ones that have the characteristics that they are ad-supported, are heavily based on UGC content, and incorporate viral marketing. If you were *just* to consider the advertising portion, then it might be easy – the LTV of a user would be defined as:
The stream of all previous and future ad impressions that a user generates from their usage
So that seems pretty clear – if you’re a user who generates 100 ad impressions a day, you are worth more than someone who generates 10.
The problem is when you try to incorporate the value of the UGC that a user generates, or the users they help acquire (or retain!) as part of the LTV calculation. And for this discussion, let’s go back to talking about Forbidden.
Forbidden as an LTV outlier
The problem with a user like Forbidden, and possibly even more so Tila Tequila, is that only a small amount of value that they create comes from their actual usage of the site. Instead, they provide additional value through user acquisition, retention, and content creation that is poorly measured by the definition above.
Another way to think of this is that if you were to remove these users from MySpace, you would not simply be subtracting their LTV from your overall site’s value. In fact, it would be an outsized decrease in value, since users like Forbidden and Tila Tequila bring many millions users onto MySpace, and entertain millions of people, keeping them on the site.
A couple commenters of my LTV in casinos blog post said as much:
Social network death spiral: How Metcalfe’s Law can work against you
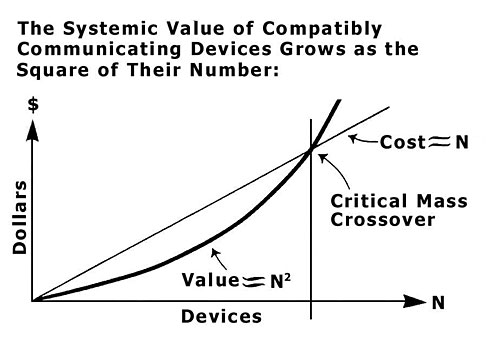
Metcalfe’s Law
Does everyone remember Metcalfe’s Law? It was formulated by Bob Metcalfe, the inventor of Ethernet and co-founder of 3Com, who stated:
The value of a network is proportional to the square of the number of users of the system (n²).
For those that are interested in the math behind it, basically the idea is that if every new node in the network connects with every pre-existing node, then as you gain nodes, you non-linearly increase the number of connections that everyone has with everyone else.
That’s pretty neat, and for the social networking folks who are aggregating large audiences and treating their businesses like communication utilities, it’s both logical and helpful to think that these social communities abide by network effects like Metcalfe’s Law. In fact, it’s a DIRECT reason why these networks want to get as big as possible, and have a social graph that’s as comprehensive as possible, and why they should ultimately be opposed to Data Portability. And I think we’ll see these players’ strategies ultimately reflect these strategies.
But Metcalfe’s Law can also affect social app creators. Let’s discuss how this might play out for folks who are building apps on social platforms, rather than operating the social platforms themselves:
“Jumping the shark” and Metcalfe’s Law
In a previous post, I wrote a bunch about how dangerous (and easy) it is to jump the shark in an enclosed space like the Facebook Platform.
Here’s the good scenario:
Let’s say that you retain users well, and you don’t get a sharkfin graph on your traffic. In that case, if you combine the two ideas – Metcalfe’s Law and with the viral loops on the social platforms – you can imagine that in the success case, you are creating N^2 value with very large N.
For folks building application on Facebook, Opensocial, etc., it’s nice to think that your new app is gaining value much faster than if you built your own
destination site. This allows you to get the N^2 benefits of Metcalfe’s Law without incurring significant costs of acquisition as you scale N up to a large number. This the best of both worlds.
Here’s the bad scenario:
Let’s consider the other case, where your app’s retention sucks, and you are going through the sharkfin graph of rapidly acquiring users, hitting a peak, and then falling down:
(scroll past the image for more)

Now all of a sudden, Metcalfe’s Law works against you – for this, I will introduce the corollary, Eflactem’s Law.
Eflactem’s Law
Funny enough, everyone always talks about Metcalfe’s Law like it’s a good thing, and they say that because they assume that N is increasing! But let’s consider the opposite: If Metcalfe’s Law says that your network grows value competed by N^2, then Eflactem’s Law states the reverse. It says:
As you lose users, the value of your network is decreases exponentially (doh!)
That is:
- If you have 100 users, and then grow to 200 users, your “value” has increased from 10k to 40k.
- But if you START with 200 users, and end up with 100, then you are going from 40k in value to 10k in value.
And that sucks. Perhaps this should be called Murphy’s Law instead?
In fact, you see this happen all the time at dinner parties or events. Things are great until one or two people announce the intention to leave. If those folks are fun and entertaining, there’s an immediate realization that the quality of the experience is about to go down. And yet more people announce their intention to leave, and so on, until you are left with the party hosts and a big mess ;-)
Advanced discussion: Social Network Death Spiral
Now let’s do a more advanced discussion using the concepts above – for some new readers, this discussion might completely be incoherent ;-)
Let’s consider a specific scenario where a social network could easily start to “Death Spiral” – here’s some set up on the scenario:
- You have a bunch of users, let’s call the total number N
- The total number of users in the ecosystem, called the carrying capacity, is variable C
- These users all individually require some utility value on a site, let’s call this V_required
- Then there’s a retention %, called R, which depends on two factors:
- If the utility value for users is satisfied, that is, V > V_required, then R close to 100%
- If the utility value drops under V_required, then R is crappy, closer to 0%
- And to borrow Metcalfe’s Law, the value of the network is calculated at V = N^2
So the scenario is that as the total users for the application reaches the carrying capacity, you basically hit a point of maximum saturation – this is defined by the ratio N/C. Sometimes this ratio can also be referred to as the “efficiency” of a user acquisition process, which relays how many people you actually acquire versus the universe of all users. (Obviously you want this to be as large as possible)
Once you hit the carrying capacity and acquire all possible users, N is at the highest point, and thus the network value is also at its highest point, V = N_max^2. Similarly, because the network value V is at its highest, the retention reaches its highest point as well.
The question in this scenario is, at any point during the growth of the network, does the network value V exceed the required value of the site, which we call V_required? Does the network break through the critical mass of value?
If so, retention should be great, as defined by the explanation above. In fact, maybe you reach V_required early on during the growth of the site, which makes the acquisition process much more efficient. Early on, maybe the userbase wasn’t sticking, but a critical mass threshold is met, and suddenly the entire userbase sticks, which creates a long-term creation of ad impressions and company value.
However, if you don’t reach the required value in the network, then you’re pretty much screwed. Then the retention sucks, since the users aren’t finding value, and some percentage of them will leave. This will then remove more value from the system, causing yet another round of users to leave. This continual loss of users is a death spiral that collapses your network in fine Eflactem’s Law style.
A very interesting variation of this is when you apply Metcalfe’s Law not to the entire network of users, but rather think of a social network as a loosely grouped set of connections. In that case, some local networks might have achieved critical mass, and if they are big enough, they will be retained. However, if the smaller networks around any given group start collapsing, then sometimes even the large networks will get pulled down with them.
Conclusion
To summarize this post:
- Gaining users is great, but preventing the loss of users is also very important
- Creating a sharkfin graph on your traffic means exponential descruction of value
- Critical mass plus network effects implies that complete collapse of networks is possible too
As always, comments and questions are welcome.
GigaOm’s “10 Blogs We Love” and 15 Blogs that I love!
I’m excited to see this blog on GigaOm’s recent post, 10 Blogs We Love. Thanks to Om and team for including me on the list.
Some of my daily reads that may or may not be in your reader already:
- NewTeeVee: Online video, digital television, content syndication, etc.
- YPulse: Teen trends, attitudes, products, and companies
- Bronte Media: Online advertising, market analysis
- Raph Koster: Game design, social gaming
- Slideshare Most Favorited: Top presentations from Slideshare
- Marketingcharts: Recent data, charts, and info from marketing companies
- Agenda: Luxury goods market, global marketing
- 500 Hats: Dave McClure’s blog on Facebook, social platforms, metrics, etc.
And for the totally fun, off-topic stuff:
- Bossip: Celebrity gossip about black stars
- TheDirty: hot chicks and douchebags, mostly out of Arizona’s club scene
- Wooster Collective: Street art, graffiti, etc.
- The Sartorialist: Street fashion, global style, design
- X17 Online: Paparazzi pictures, celebrity candids
- Edge.org: Big thinking, scientific discoveries and predictions, philosophy
- Arts and Letters Daily: Discussions on art, philosophy and literature
Sorry if I’ve left anyone out ;-) Hope you guys enjoy.
Online advertising report for 2007 by the IAB
The IAB is one of the major online advertising associations, and they publish a yearly report on the ad market that’s always worth a browse. Here it is:
Social network marketing: Getting from zero to critical mass

(above is a picture of fun San Francisco tradition called Critical Mass in which cyclists take over the street! Thank god I don’t drive much around the city)
What does it mean to hit critical mass?
I’ve heard several pitches in which an entrepreneur outlines a marketing plan for their business which is lots of hard work, but eventually they reach a “critical mass” point where all of a sudden magic kicks in, and smooth sailing is ahead. What these discussions often leave out is, what exactly is a critical mass point anyway? How do you know where it is, and how do you know if you’ve hit one?
To answer this question, let’s return to the original definition of “critical mass” from the Physics world:
The smallest mass of a fissionable material that will sustain a nuclear chain reaction at a constant level.
What does fissionable material means? What is the chain reaction that happens for a web property? Let’s look at it from two separate contexts – user acquisition and retention.
User acquisition
One way to interpret this is that initially, your site has difficulties with user acquisition, until you hit some scale points in terms of total userbase. Then all of a sudden, your site goes “viral” and you start getting lots of users coming in. To formalize this idea, you could imagine the following happening:
- Initially, you are getting users through ads or PR, and your viral factor is <1
- As your site grows, word of mouth effects (bloggers, friends, etc) give you some name recognition
- This brand recognition increases your conversion rates across the board, thus boosting the percentages that make up your viral factor, increasing it to >1
That’s one way of viewing it, although I don’t believe that’s what most people mean. They usually mean that their site is not that useful until there’s a certain # of people on it, and when you cross the critical mass point, then the site becomes engaging. So let’s talk about this idea in an engagement context:
Engagement
As discussed above, there’s an idea that for a user-generated content site, you have an early bootstrapping problem. If you’re YouTube, but have no content, then no users will stick around. Yet if you have no users, then you have no one to upload content. So you need to break out of this local minimum until you cross some threshold – this is the critical mass point. To formalize this idea, here’s the retention focused view:
- Early on, you are getting users through PR or ads, but all your users bounce off the site
- However, each user you acquire have some chance of creating content (profile/pictures/video/etc)
- Eventually, new users have enough content to consume that they stick around on the site, perhaps messaging older users, who now return
- Once you have a “critical mass” of users, then there’s enough activity to keep everyone coming back
In this perspective, you can imagine that there are actually multiple phases that your user passes through – initially, they have a passive experience where they are pulled back onto the site because of notifications like friend adds, messages, etc. And it’s possible for your site to never get past this phase. However, if you acquire enough people, new users pull back old ones, who then start coming back, until they start using the site on a regular basis.
What “scale” of network does your website depend on?
However, the discussion above also neglects that users want to consume different kinds of content depending on how they view the site. For example, the following scenarios are probably FAIL states, even if on the surface they look good:
- 1,000,000 users composed of 100 strangers in 10,000 different locations
- 1,000,000 users who created 1,000,000 different forums with no cross-visiting
The reason is that the above scenarios represent ultra-fragmentation, with no ability to reach critical mass points. This illustrates that there are different scales of network, which reflect different product designs. These include:
- Networks of “real friends”
- Networks of online friends united around an activity or interest (WoW, anime, etc)
- Networks of people in the same local region
- etc.
some applications only need a small number of friends to get off the
ground, and others need more:
- Skype: 2 minimum
- Mailing list: 4-5 minimum
- Forum: 10 minimum
- Social network: 10? 15? 20?
- … etc.
So I’d encourage anyone building a social site to really consider what type of network they are building for, and how many people they need at the local level. Once you can figure that out, then the next goal is to aggregate these smaller groups into a larger one. This is essentially what Facebook did – by understanding how to dominate a smaller space like a college, they could roll up lots of small spaces into a larger population.
Aligning your user acquisition to your network goals
As many have observed, startups working on the Local space have had a very very tough time, with the exception of Yelp. In Seattle, where I’m from, Judy’s Book raised a ton of money and then promptly closed shop because it was hard to get traction.
The reason of course, is that a regional network is a pretty specific one – there are tons of them – plus the minimum social group is actually pretty high. You need a lot of diverse people on the site, reviewing everything in site, before you hit a reasonable coverage % for reviews.
Similarly, if you are doing blind addressbook importing as the way to grow your userbase, but you aren’t targeted about what traffic you’re pointing into the viral loop, then you might end up with a bunch of users from Turkey or some other random part of the world. Probably also not what you wanted.
So to review:
- Critical mass is defined by what type of network your social product operates on, and how many users you need on that network before the product becomes useful
- Thus, critical mass is a product-by-product discussion – there’s no one-size-fits all
- Similarly, people that use your product go through a collection of “phases” – from ranging from passive usage where there isn’t enough content to consume, to the point where they are very active and creating content themselves. The threshold point between the phases is a local observation of critical mass
- Sites that are useful for “online friends” and don’t require too many people are the easiest to get off the ground (but have other issues, like they might be too niche)
- Site that are useful only for large numbers of “real life friends” (local review sites are a good example) are the hardest to get off the ground, yet are hugely useful if you can get people on board
As always, comments appreciated.
Lessons from the casino industry on engagement metrics and lifetime value

Great book covering the modern casino industry
I recently
stumbled on "Winner Takes All," which is a great overview of the modern
casino industry starting with Steve Wynn, Kerk Kerkorian, and Gary
Loveman. It starts out mainly talking about the amazing vision of Steve
Wynn, and how he was able to create some of the world’s more expensive
and opulent casinos, including the Mirage and the Bellagio.
In it, they also talk about a bunch of techniques that the casinos use
to maximize on revenue, including vertical integration, in which they
build "cities within cities" at a casino, so that you can eat, sleep,
shop, entertain, and gamble all without leaving a single complex.
(scroll below for more)
Harrah’s, the casino run by quants
The big story for me was the formation and operations of Harrah’s, which mostly constituted lower-tier casino boats for much of their history. They were decidedly unglamorous, and seemed uncompetitive to the entire high-touch Vegas scene. Think of them as Wal-Mart of casinos, versus Wynn’s Prada of casinos. Whereas the Vegas casino scene was very focused on "art" and the creating massive experiences, Harrah’s was run by the numbers and very methodical about how they grew their business.
Harrah’s eventually became the largest casino company in the world, and is led by Gary Loveman, who got his PhD in Economics from MIT. And they grew their business like a business run by a quant. Here were the major steps they took, as outlined from the book:
- First, they created a loyalty card to centralize identities and create consistent experiences
- They created a granular calculation of LTV for their customers
- Then, Harrah’s segmented their key clients based on usage, and then based on "lifecycle"
All in all, a very interesting approach – I jotted down a couple notes as I was reading the book, and wanted to share some of these thoughts below:
Building a single identiy – the loyalty card
Unlike on the Web, it’s not easy for businesses to keep track of their customers – this becomes a big problem in an industry like gambling, where a small % of your customers make up a big % of the profits (aka, these guys are the "whales"). So if a gambler went to their regular Harrah’s casino, people would recognize them and they’d get differentiated service – but if they went to a different Harrah’s, for example on vacation, their history didn’t follow them. That way they couldn’t differentiate between the $100k spender versus the casual looky-loo, which was bad for business.
So Harrah’s introduced a series of loyalty cards called Total Rewards, which were used for "comps" and other free stuff. For the games folks out there, notice that you can "level up" as a member from Gold, Platinum, Diamond, Seven Stars, and for one member – Harrah’s "best" customer – there’s a Chairman’s Club card. They go so far as to fly you around, give you free hotel and accomodations, and other great perks.
This loyalty card gave them the underlying data which they could now use to drive the other parts of their data strategy.
LTV on a per-user basis
The next step once they had all this data was to create models against the lifetime value (LTV) of their customers. This was done in two ways – first, you can imagine a visit to a casino, where a customer comes in, plays cards/slots/whatever, and then leaves. Based on their actions, a "theoretical win $" is calculated, which is an expression of what the casino should expect to get from that person. Combining this number and other services consumed and comps, you end up with a net profit calculation. You can imagine that this number is a rolled up view of:
- How much money that person brought with them
- What games they played, in what mix
- How long did they play for
- What other services did they consume
- etc.
Once you can value an individual session, then you can also chain together multiple visits to calculate an aggregate value. This means that you can now tell the approximate difference between a rich customer that visits every July 4th, once a year, versus someone who plays frequently but also spends less money.
Targeting based on customer lifecycle
Josh Kopelman from FirstRound Capital recent wrote a great blogpost called Lifecycle Messaging that I’d encourage you guys to read. It basically talks about the lifecycle of a customer, and how you want to send them differentiated messaging based on what stage they’re in.
Harrah’s did exactly this – once they had the ability to model out a customer’s LTV, then when new customers arrive, you can start to put them into buckets of profiles that are already "like" them, in order to predict future LTV. Then based on LTV and their stage in the lifecycle, you can start to do some very interesting things: For new high-value customers, they can try to engage them quickly and get them highly personalized service right away, so that they’ll stick. For low-value customers who don’t fit the Harrah customer profile, it may be better to ignore than group than spend too much cash chasing it.
One of Harrah’s most profitable customer segments turned out to be older, retired gamblers who came by very often, and mostly played slots. They called these guys Avid Experienced Players (AEPs) and targeted this group for both new customer acquisition as well as retention. This group was not the "whales" of the Vegas casinos, but had a similar financial heft to the company.
Conclusion
There’s a ton to learn from external industries, and I’d like to add casinos as an interesting place to extract lessons for Web entrepreneurs. It has an interesting blend of quantitative data, in gambling transactions, as well as the qualitative, which drive the emotions behind why people prefer the Bellagio to other hotels. It’s one of the industries that is at a fascinating intersection of both, and like the social web, you need both perspectives in order to thrive.
Has the Facebook platform hit its peak?

The state of the Facebook platform
Jesse Farmer, formerly of Adonomics, has posted some great analysis on the state of the Facebook developer community. In short, if you take the Facebook developer forums as a proxy for overall activity, the indicators across the board have declined. Now, you might argue that this isn’t a fair proxy (and there’s some analysis in the article on that specific point), but I’d argue it’s a pretty good one to use in order to gauge overall interest and the health of small/medium developers.
In particular, Jesse includes this great table summarizing the data around the Facebook dev forums:
Monthly Statistics for the Facebook Developer Forum Month: Jan 2008 Apr 2008 Posts per day 461 225 -51% Signups per day 38 27 -29% Threads per day 80 44 -44% Active users 1,606 1,168 -27% Highly active users 461 225 -47%
As you can see, there’s been a decline across all indicators.
Similarly, if you take one of these factors, let’s say Posts per week, and look at the overall historic trend, you can see that Posts Per Week peaked in the late Jan / early Feb timeframe, and has significantly decreased from there:

Note that MA in the above graph is "4 week moving average" meant to smooth out the ups and downs.
Key issues facing the FB platform
He further hypothesizes a number of different issues going on, including:
- Other platforms are more attractive
- Developers are consolidating
- Facebook has made it too hard to win
Overall, a great analysis – would definitely recommend that you read the full article here.
Facebook Apps: Why they’re focused on fun instead of utility

There’s recently been some discussion that Facebook apps are silly and pointless, as proven by the categorization of apps on Facebook. The question is, why is this true?
Ben Rattray from Change.org recently sent me a great e-mail, and I asked for his permission to blog the essay. In it, he discusses the structural issues around Facebook apps, and why they encourage apps focused on communication rather than utility.
[UPDATE: Just to be clear, everything underneath the following line is Ben’s work – one of my readers wanted me to clarify]
Ben writes:
The
reason there are few and little use of utility-based applications is
not because users don’t want to use them or because app developers
don’t want to develop them, or even because Facebook doesn’t want to
encourage them (which they clearly do). It’s because the means of distribution inside Facebook are structurally biased against them.
As you know, the reason for this is simple math. The only way for a Facebook app to get any sort of distribution is to have a viral coefficient over 1. This
is an extremely high barrier for any app in which inviting friends is
not an inherent part of using it (or, in your parlance, in which it is
not structured for "viral action").
Instead,
what most utility-based apps rely on for distribution is word of mouth,
in which people tell their friends not because there is something built
into the app that naturally causes peer-to-peer transmission but simply
because it’s worth talking about – or, in your parlance "viral
branding." And as you’ve written it is very difficult to achieve a viral coefficient of over 1 through word of mouth. Ironically,
this difficulty is compounded inside Facebook because the proliferation
of viral action apps inundates users with invitations and makes them
less and less likely to accept anything – including invitations to
utility-based applications. So the barrier for going viral increases even further. Given
current invitation conversation rates of 5% or less (at least what I’m
hearing), for an app to go viral, you have to get people to invite an
average of at least 20 friends. How many utility based apps can achieve that? How many inspire so much passion that its users tell 20 friends, on average? Few, even if people find the app incredibly useful.
(Of
course, there are other ways that Facebook apps can be distributed
outside of explicit invitations – i.e. the news feed and profile – but
these are not nearly as effective as invitations and it’s very
difficult to go viral on these channels alone. Also, few
people want to highlight their "utility" apps on their profile since,
by definition, these apps are less about self expression, which is
largely the point of the profile.)
To
see how singularly biased Facebook’s distribution structure is against
utility-based apps, a comparison with the platform it so often likes to
compare itself to, Windows, is instructive. Many Windows
applications are incredibly useful, but few of them are viral (those
that are, like Word, are only so because the use of it requires that
others have it as well, and because they are increasingly useful as
more people have it – e.g. they have network effects. But this is rare and they take a long time to gain traction). Instead,
the way most Windows-based applications get distribution is through
traditional, boring marketing and distribution deals with big-box
stores like CompUSA.
But it’s very hard (and incredibly inefficient) to market apps outside of the walled garden of Facebook. And
nobody has the budget for true Windows application-style marketing
since there is no clear business model yet inside Facebook to justify
this sort of ad-spend. So the only way apps can get distribution on Facebook is by having a viral coefficient of over 1.
(This
is also why there is a wide chasm in the installs between apps – either
an app is viral and has millions of users or its viral coefficient is
less than 1 and has only a few hundred or few thousand users. It’s simply mathematically impossible in a closed system for apps that aren’t viral to get any traction. And
this is not because all apps with a viral coefficient of less than 1
are not found useful by its users – it’s because no more than a few
people will ever find them.)
Theoretically Facebook’s "application directory" could serve as the virtual equivalent to CompUSA. But there are so many applications in the directory that it is rendered virtually useless. This is a clear situation where too much choice is paralyzing – e.g. the "paradox of choice." Imagine walking into a CompUSA and having 25,000 choices for different applications. It’s just not possible to decide between so many options. And so your natural reaction would be to just to walk away and never come back. And
that’s how it seems most Facebook users have responded to the
application directory – there are very few installs directly from
there, and I suspect it’s never used much. (And, to the extent that it is used, the largely trivial viral action apps always dominate the front pages.)
Anyway, I realize that this is all already stuff you know, but it’s remarkable that nobody seems to be writing about it. Instead what we get the glib analysis that all Facebook users want are trivial apps. And
while it may be true that "just for fun" and communication apps are the
ones users enjoy the most, that is far from the complete story and
overlooks much deeper structural impediments to utility. It is also based on the misguided presumption that apps that are installed the most are those that users like the most. Which is simply not the case.
As
a final note, I’m not sure what you think, but it seems almost certain
that Facebook itself didn’t realize when they launched the platform
that they created a system in which it was nearly impossible to achieve
the very thing they claimed to seek – greater utility. They
now seem to understand the problem and are trying to take measures to
improve the situation, but to do so they’re going to have to either
tweak things to make it possible for useful (but not inherently viral)
applications to have a viral coefficient of over 1 (very difficult, I
think), or they’re going to have to implement a much improved directory. They
could also personalize the directory so that users could see all the
applications their friends rated most highly (not just used).
Either way, this is a big problem for Facebook, but not the one that most people think. It’s not that users or application developers don’t want to use or build useful apps. It’s that Facebook’s current structure is heavily biased against them.
[Ben sent me the following afterwards, as some extended remarks -Andrew]
Extended remarks:
After
re-reading what I wrote as well as the comments below, I realized I
should have probably also addressed the following two things in my
original email:
First, what do I mean by a utility-based app?
Second, should Facebook aim to be a utility?
To
answer the first question: by utility I don’t just mean applications
that are in the "utility" category of apps on Facebook or any sort of
web application that might be considered generally useful. Rather,
I mean it in the particular way I take Zuckerberg to mean it: an app
that leverages the social graph to create greater social and personal
value.
Definitions are important here. To
illustrate exactly what I do and don’t mean, I’ll outline what I
consider to be the three broad categories of web applications that
might be considered to have utility:
- Apps that are inherently social and which let users better coordinate/connect with friends
This
first category includes applications that help people coordinate or
connect with friends or others in ways that are traditionally difficult
but which the social graph makes relatively easy and potentially very
powerful. (These are distinct from "just for fun" games and
other playful communications in that they generally help people
accomplish something concrete.) For example, these might be apps that:
- Help people organize local sporting event leagues
- Share travel schedules with friends (ala Dopplr)
- Organize carpooling
- Discuss and coordinate events / gatherings with friends (ala Skobee)
- Allow
for the creation of affinity groups that require custom features not
available in the traditional "groups" feature set (e.g. Alcoholics
Anonymous groups, as humorously suggested by Max Levchin recently)
Because
of the inherently social nature of these potentially useful apps, many
of which involve inviting friends, some of them may have the potential
to have a viral coefficient of over 1. But they face a
big hurdle in sustaining a viral coefficient of over 1 for many
successive generations because (1) a large percentage of users get
value out of the app without needing to invite further friends, and (2)
although there may be a lot of people interested in the app and in
inviting all their friends, these enthusiasts are not socially
connected tightly enough to allow for the continued transmission of the
app across personal networks. For example, someone might
create a custom carpooling app and invite a lot of friends who are the
type of people who would themselves push it to many other friends they
want to carpool with, but because this social group may be socially and
geographically isolated from other groups of friends passionate about
carpooling, the app’s viral coefficient will fall below 1 as it hits a
population of people less interested in passing it on and its organic
distribution will rapidly exhaust itself before being able to reach
other interested populations – at which point few people will ever be
exposed to the app again. And this is despite it being considered a very useful app by many people.
2(a). Apps that aren’t inherently social, but which are given enhanced value with the social graph (non-business / work)
This
second category includes applications that may not be intrinsically
social or interpersonal (and therefore may exist independent of a
user’s social graph), but are those which gain additional value when
laid on top of the social graph. This includes apps that allow people to:
· Share news (e.g. a personalized Digg)
· Share
restaurant / service provider reviews (e.g. a personalized Yelp – so I
don’t just get undifferentiated restaurant reviews, but only those from
people I trust)
· Share bookmarks (e.g. delicious with all my friends)
Note that the three examples I’ve given already have canonical applications outside of Facebook. Despite
this, I think that the social graph offered by Facebook has a lot of
value to add in that would allow me to receive the recommendations
generated by these services through the trusted channels of all my
friends.
It’s
also noteworthy that all three companies did launch Facebook apps and
that none of them received more than a few thousand installs despite
their huge popularity and the extra value offered by Facebook’s social
graph. This is clear evidence of what I mentioned above about the systematic distribution bias against utility-based apps.
2(b). Apps that aren’t inherently social, but which are given enhanced value with the social graph (for business or work)
A
subset of this second category are apps that, while given enhanced
value by the social graph, are structured for work and therefore a bit
of an odd cultural fit for Facebook even though strictly they could
benefit from being inside the platform. Examples include apps that allow for:
- Job seeking / networking
- Collaboration on work / documents
I
think it’s an outstanding question whether these are appropriate for
Facebook, but I’m skeptical they will ever be (just as I’m skeptical
Facebook will ever replace Linkedin for business networking). Just
because something can fit inside Facebook from a functionality
standpoint doesn’t mean it will fit the site’s culture, and culture on
social sites matters.
- Apps that are neither inherently social nor benefit from the social graph (but are still "useful")
This
final category are web applications that are useful (like purchasing a
plane ticket, managing your finances, etc) but which don’t at all
benefit from the social graph. It’s clear these types of apps don’t have any business being inside Facebook.
So,
in summary, when I say "utility-based apps" I mostly mean apps that fit
in categories #1 and category #2a, but not those in #2b or #3.
Given this definition, should Facebook strive to be a social utility? Or should it just focus on what it’s clearly great at – personal communication and play?
To answer this question I’m first inclined to ask the more fundamental question, "do people want Facebook to be a utility?"
The
problem is that I’m not sure you can give a great answer to this yet,
since the biased nature of app distribution on Facebook means that most
people aren’t being exposed to utility based apps – so we just don’t
know yet how people would respond if these apps had widespread usage.
I think it’s possible that Facebook users as a whole just aren’t that interested in utility-based apps. But
I also think that a strong argument can be made that Facebook could be
a compelling utility (as evidenced by some of the examples I gave
above), and that the value of it becoming a true social utility is
great enough to justify aiming for this. From a business
standpoint, if Facebook wants to keep their core audience engaged
beyond college, attract an older audience that has never used Facebook,
and better monetize both groups, they’re going to do more than offer
fun ways to communicate with friends.
The
challenge, of course, is to figure out how they can give themselves a
legitimate chance of becoming a social utility with the current app
distribution problems I described above. Frankly, I’m not
sure whether the Facebook platform is the best way to achieve this, and
I personally think they would have been better off focusing on an
improved remote login API that allowed users to pull their social graph
into third-party sites and then pump personal data back into Facebook
ala FriendFeed, and that contrary to all the hype the platform may have
been a strategic mistake. But that is another story entirely…
Ben Rattray is Founder and CEO of Change.org and lives in San Francisco

Quick link: Movie versus video game
Interesting that there’s a full article on CNN that a video game might substantially impact the opening day launch of a movie: ‘GTA IV’ could keep ‘Iron Man’ audience at home – CNN.com.
Would you have entertained this as a problem years ago?
The aggregate industry numbers prove it out – in 2007, the movie box office is $9.6B and games is $9.5B. It’s neck and neck!
UPDATE: A couple readers have pointed out that the movie numbers obviously don’t include DVDs, licensing, and lots of other revenue streams – it’s still an amazing comparison, but doesn’t fully capture movies versus games
Vertical ad networks: What are they, and why did Cox just buy Adify for $300MM?

Adify exits for $300MM exit
Some of you may have read about the acquisition of Adify by Cox for $300MM. It’s been covered in PaidContent, Silicon Alley Insider, and scores of other places. You gotta love the online ad industry – if this had been a consumer internet exit, it’d create intense buzz throughout the blogosphere, but since it’s a boring B2B infrastructure play, it likely bores most people.
Anyway, I wanted to jot down a couple notes about how the industry fits together below – by the end, hopefully you’ll get what Adify’s business as a "vertical ad network infrastructure" company is all about.
What is a vertical ad network, and why would you start one?
The vertical ad network business is like the startup recipe du jour of New York. I’ve been pinged many times over by folks who are looking to start one, companies pitching them. Basically, these networks are appealing if you fall into the falling description:
Ad sales dude: You can sell ad impressions better than you can generate pageviews
Compare this to the typical Silicon Valley entrepreneur, who suffers from the opposite problem:
Web 2.0 dude: You can generate pageviews, but have no idea how to monetize them
So if you’re in ad sales, and you can monetize but can’t generate pageviews, what do you do? Well, you have several choices:
- You can work for an online publisher (like ESPN/NYT/etc)
- You can work for a rep firm or ad network (like FM, Ad.com)
- You can work as an outside sales rep for a publisher
- etc.
Now the last one starts to get you into vertical ad network territory.
Starting a vertical ad network
Let’s say that you start by representing the ad inventory of a sports site, and you do a good job pitching ad agencies that represent Nike, etc. To become more relevant, and to lift all boats, you want to get MORE ad impressions, so that you can provide more reach. So you go sign up another sports site, and another, until you have a huge aggregation of the biggest sports publishers out there. At that point, you probably have a big team to do things like run your ad server, optimize the campaigns, and you might be an exclusive provider of ads to some of the sites you’ve signed up. And thus, you’re a vertical ad network.
The biggest issue is channel conflict, which you can easily avoid. The problem is that a site like ESPN would never want to join an ad network, because they sell their inventory at premium CPMs that few would be able to approach. As a result, the only way to make this work is to form a vertical ad network with long/mid-tail publishers that don’t have direct sales teams.
So in summary:
Vertical ad networks = Ad sales guys + Lots of mid/long-tail publishers in a vertical area
Basically, like all ad things, it’s a type of arbitrage based around access to relationships and skillset, which converts <$1CPM ad inventory into something many times that. Then furthermore, the dynamics that encourage this market:
- Ad sales guys often suck at creating new pageviews, but can monetize them
- Web guys often suck at selling impressions, but can make websites
- Brand ad agencies reward REACH – so a bunch of small guys together is better than by themselves
- A good ride for the economy in the last few years has increased brand spend online (which will continue)
What’s a vertical ad network infrastructure company?
Now that you know what a vertical ad network is, then it’s easy to define a vertical ad network infrastructure company. Basically, if you want to set up a vertical ad network, first you need some sales guys, but you also need a bunch of software that lets you do stuff like:
- Managing what publishers are in your network
- Billing and payments
- Campaign management
- Ad serving
- Setting pricing and outlining inventory
- Creating an automated marketplace
- etc.
So if you’re 3 salesguys out of a financial services publisher, for example, you don’t have to build the above – instead, just sign up for a license, and you can start selling from there.
I think where this fits into Cox is that they are ultimately a huge Old Media company – cable, media properties, newspapers, etc. They are seeing their ad revenues erode over time as the eyeballs move online, and their audiences aren’t sticking to their online properties either. But as an organization, they know how to sell to advertisers, and this acquisition makes them able to leverage their skillset across many different verticals and domains online.
How do vertical ad networks fit into Web 2.0 and UGC?
It’s important to note that vertical ad networks have a huge role to
play in the eco-system of Web 2.0, because they are one of the only
ways UGC content is being monetized well. Essentially, as consumers
move to social sites, the skillset to package, sell, and manage the ad
inventory for brand advertisers has been "outsourced" to these vertical
ad networks – the guys that start the websites just aren’t typically
strong in this area. As a result, this process allows brand advertisers
to talk to intermediaries that understand their concerns and help them
make the jump into buying UGC inventory.
Just look at the list of clients that Adify has, many of whom are based on UGC ad inventory.
Summary
In short, this entire space of vertical ad networks is created by the inefficiency in brand ad sales, which is likely to just continue. Let’s hope that it becomes a sustainable way for smaller publishers to monetize their inventory, rather than just dumping their ads into remnant ad networks.
As a quick plug – there are not many folks in this space other than Adify, but I share an office with AdRoll, another company that’s doing vertical ad network infrastructure. I’d encourage you to check them out, since my guess is that this area is about to heat up a lot more.
Facebook app CPM numbers from Inside Facebook
CPM rates on Facebook apps
Great data from Justin Smith on Facebook app CPMs: What CPM is your app making? Data from Facebook Developers. Thanks to Justin for putting together these great numbers.
Here are the numbers:
- tspree15 is making $0.60 CPM with Social Media
- cbovis is making $1.50 CPM with VideoEgg, but they can’t cover all his inventory (the rest runs on RockYou)
- sweetsteve is making $0.27 CPM with Cubics, down from $0.43 earlier this month
- ejono is seeing a $0.40 CPM with Cubics
- cory is making a $4.78 eCPM with Social Media (???)
- mzeitler
is making a $0.50 CPM each with AdSense, FB Exchange, Social Media, and
RockYou (and by combining 2 units on a page is making $1.00 CPM) - saintseiya is making $0.125 CPM with Lookery ($0.25 with 2 ads above the fold)
- markdoub is seeing $0.10 CPM with Cubics, down from $0.43
- ersingencturk is seeing $0.04 CPM with AdSense
Overall, the numbers are generally <$1, and you also see that there are some issues with "fill rates" – that is, how likely it is that an ad gets displayed when there’s a space. For brand advertising, it can be quite low.
How does this foot to internet-wide CPMs?
These numbers are in-line with my previous post on 5 factors that determine your advertising CPMs, where I wrote:
- Social sites (forums/chat/etc) without direct ad sales teams: <$0.25 CPM
- Largely international sites: <$0.50 CPM
- Medium-sized sites that use banner ad networks: <$1 CPM
- Reference sites in a specific category: >$5 CPM or sometimes
much higher, depending on category – we ran into home improvement
reference sites that did $20 CPMs
Given that these are all social sites with mostly US traffic but no direct sales teams, an average of 10-50 cents is pretty accurate.
Combine this with Jeremy Liew’s insights on getting to $25MM/yr on Facebook app ad impressions, and you see that it takes a good 900+ million installs. Ouch. Jeremy’s slides below…
When will Slide release their hounds on the social gaming sector?

I have huge admiration for the Slide guys how they are dominating the new industry of social apps, using deep skills in viral acquisition, metrics, and consumer psychology. So when their CEO makes a dramatic statement about the internet economy, it’s worth paying attention.
There was a recent quote in Valleywag about the impending recession and how Slide views it: Slide’s Max Levchin: It’s time to shift away from advertising.
Worried about an upcoming recession, PayPal cofounder Max Levchin told News.com that his company, Slide, is "trying to shift away from advertising partially" and go "direct to consumers" for its revenues. "It cuts out one more party from the equation," Levchin said.
Wow – "direct to consumers" – I wonder how long it’ll take before they announce a direct product in the social gaming space. After the recent funding events for Zynga, SGN, Friends for Sale, and others, it would be the next logical step.
I’ve written extensively on the topic of virtual goods for Web 2.0 web properties: Forget advertising – are virtual goods the killer revenue model for Web 2.0, What every Web 2.0 entrepreneur should know about virtual goods, and 5 things that make your social network monetize like crap.
To summarize these posts, the movement towards looking at virtual goods to monetize social sites comes from a combination of factors:
- Brand advertising on social networks is quite hard, and quite slow
- With the larger economy experiencing a downtown, brand advertising will take a big hit, making new ad unit types harder
- There’s widespread consumer familiarity with games and game mechanics
- Large-scale existence of virtual good economies exist (particularly in Asia)
- There continues to be a casual-ification of games, making them more social, less time-intensive, and more like social networks
It’ll be very interesting to see how this works out.
10% discount off of the Social Gaming Summit
My buddy Charles Hudson is putting on a conference on social games, and I wanted to share the details. I you use the discount code ANDREWCHEN, you’ll get 10% off.
See you there!
Details below…
Conference description
The
Social Gaming Summit is a one day conference focused on the
intersection of casual gaming, immersive worlds, and social networking.
Games are
becoming one of the most popular activities within social networks and
game
developers continue to spend increasing amounts of energy figuring out
how to leverage and apply the growth in social networking to the games
they are developing. The conference will bring
together leaders in the social networking and gaming spaces to share
insights
into the convergence of these worlds.
What: Social Gaming Summit (http://www.socialgamingsummit
Where: UCSF Mission Bay Conference Center, San Francisco, CA
When: Friday, June 13th 2008
Register Here: http://socialgamingsummit
Confirmed speakers already include the following list of folks:
Dave Williams, Shockwave and AddictingGames- Craig Sherman, Gaia Online
Jim Greer, Kongregate
Siqi Chen, Serious Business (Friends for Sale)
Erik Bethke, Go Pets
Daniel James, Three Rings
Amy Jo Kim, ShuffleBrain
Nicole Lazarro, XEODesign
Matt Mihaly, Sparkplay Media- Shervin Pishevar, Social Gaming Network
- Mark Pincus, Zynga
- Jeremy Liew, Lightspeed Venture Partners
- Mike Sego, (fluff)Friends
- Kyra Reppen, Neopets
The Social Gaming Summit will focus on a number of important themes in this emerging market:
- Monetization and Business
Models for Social Games - Casual MMOs and Immersive Worlds
- Asynchronous Games on Social Networks
- Building Communities and Social Interaction In and Around Games
- What Makes Games Fun?
Viral marketing, activation, and retention metrics – commentary on Dave McClure’s Web 2.0 presentation
I wanted to share Dave McClure‘s talk at Web 2.0 – it’s evolved over the last year, and shows some learnings from the Facebook world:
Some quick comments
In general, I agree with Dave’s view of the world, and he does a good job breaking down each specific component:
- Acquisition
- Activation
- Retention
- Referral
- Revenue
A couple notes on each section:
1) Acquisition
Dave’s slides list a multitude of acquisition options, from SEO to blogs and PR, to e-mail, etc. And while I was at MDV, I often saw pitches that incorporated a huge laundry list of acquisition strategies, which generally made me think the entrepreneur pitching didn’t have a strategy at all. In general, the main thing to focus on is that you have a scalable acquisition strategy. That is, you have a single strategy that has the potential to get you up to 1,000 users or 10,000,000 users or more.
The reason is that fundamentally, the science of acquisition requires that you specialize in a particular area, and invest resources such as:
- Building out analytics
- Conducting A/B or multivariate testing experiments
- Being creative and trying out different variations as strategies
- Keeping up with other folks who are using similar acquisition strategies
The point is, if you pick one of the really scalable techniques, for example Facebook/OpenSocial, or SEO, or e-mail virality, it requires an immense amount of time and effort to kick ass at it. Anyway, I don’t think Dave’s slides say otherwise, but I wanted to emphasize that acquisition is an entire area in itself, and is worth focusing on.
2) Activation
The activation slides are solid, and I’ve written about a similar topic except focused just on virality. To sum up my post and how it relates, the point is that if you have low efficiency, that actually hinders your growth substantially once you hit network saturation.
For example, in the Facebook universe (60 million users), even if you are growing exponentially, let’s compare an activation efficiency of 5% rather than 20%:
- 1 in 20: total universe of 3 million active users
- 1 in 5: total universe of 12 million active users
So even if you’re viral, once you hit network saturation, your traffic will begin to plateau and wane. On a related note, my friend Ed Baker noted that given most Facebook apps haven’t been able to sustain >12MM installs, it tells you that most apps are not able to achieve activation rates much higher than 20%, even after they’ve been acquiring users for months and months.
Because of this, it’s a smart idea to try achieve both virality and high activation efficiency – this will make sure you have the highest potential for a large base of users. This might mean reducing your spamminess level so that you don’t hit network saturation as quickly, and targeting your invites. Similarly, you’ll want to do all the optimization suggested in Dave’s slides in order to reduce friction throughout the activation funnel, so that people aren’t leaving from confusion.
3) Retention
Two words: Cohort analysis. :-)
Retention is actually one of those places where I think you can’t let metrics drive the conversation – it’s useful for validation, but the core product experience starts with understanding users. The reason is that unlike the acquisition process, it’s easy to be "on the wrong mountain" so to speak, and metrics will help you climb this wrong mountain, but not figure out the right one to be on. The problem is that choosing the right problem to solve for the customer has a lot to do with higher-level issues, like emotional needs, cultural perceptions, and nuanced social interactions.
In my humble opinion, the right community to look at here are design folks like IDEO. By clearly defining the target customer, understanding all the soft-values that go into motivating this group, and crafting an experience that’s compelling, I think this approach gets you onto the right mountain. For this reason, this community is all about hiring anthropolgists, cognitive psychologists, and other social scientists, and then throwing them in a room with engineers, business folks, etc. A comprehensive discussion of these techniques can be found in the IDEO book Designing Interactions.
Another really interesting community here is game designers, as well. After outsourcing their distribution for the last couple decades to a couple publishers, the community has grown to focus on the gameplay experience – making them experts in retention. Some of the most interests concepts revolve around how you build up a game using "core mechanics," and how RPGs structure their point systems to create compelling reward structures. My friend Dan Cook’s Lost Garden has a wonderful repository of essays on this topic.
4) Referral
It’s very smart for Dave to separate out referral traffic from acqusition traffic, though many people treat them as the same thing. Here’s the difference:
- Acquisition traffic is often one-time traffic
- Referral traffic can be continuously generated traffic
The reason, of course, is that referral traffic puts you on the SAME SIDE as your users – you’re aligned, because the better your user experience, the better you retain your users. And the better your user retention, the more people they refer.
The question just becomes, how well can you retain users, and how fast do their refer their friends? If you can get these variables to align, then off you go, you have a scalable traffic acquisition strategy.
5) Revenue
It’s very hard. And for advertising-supported businesses, don’t focus on it until you’re at many 10s of millions of pageviews per month, because it’s hard to generate substantitve revenues until you get to scale.
Conclusion
Hopefully my commentary added some value to the discussion – thanks to Dave for putting his slides up online.
Moving to SF and joining the tech community – Lessons from my first year
Thinking of moving to the startup mecca?
I’ve now been in SF for a little over a year now, and have had many friends from Seattle and elsewhere contact me thinking of relocating as well. I’ve gotten pretty integrated into the SF tech community here, so assuming that you’re ready to go, I had a couple tips I figured I’d write down.
Here they are:
You don’t need a killer idea, and you don’t need a job offer
First off, a lot of folks at places like Microsoft think about moving to SF, but are waiting for the perfect job or the perfect idea to pop up. Problem is, from your perch at a Fortune 500 company, you just don’t have access to the best people, companies, and ideas to make a decision about the “perfect” startup.
My recommendation is just to set a timeline for yourself, and just do it! – even if that means crashing on a couple couches for the initial weeks just to get yourself integrated. Given that there’s an amazing number of tech people here, if you’re halfway competent you’ll get exposed to a ton of new opportunities that you hadn’t even heard of.
In my case, in the process of moving down I ended up taking an EIR gig – but rather than spending the time working on a company, I spent it networking and getting to know the tech community here in the Bay Area.
Start going to conferences and events
A good place to start is by meeting people – there’s no central directory of events, but they are often posted on places like:
- BASES (a Stanford startup group)
- Upcoming
- Facebook (just look at the events people are going to)
- Meetup
If you are serious about it, you can go to 2-3 events per week easily, and meet a ton of people there. In addition, you should follow guys like Dave McClure, Noah Kagan, Christian Perry, Charles Hudson, and others, since they are often in the middle of the conference circuit.
For me, I’ve helped with a couple conferences here and there – it’s a great way to get people together, and to participate in the startup community. That’s why you often see me plugging specific conferences in my blog.
Be systematic about meeting people, and keep tabs on them
Of course, once you’re at the tech events, use the time well. I wrote, almost a year ago, a blog post on the topic called 10 tips for meeting people at industry events. Similarly, make sure you use Linkedin or Facebook to connect with people and keep track of what they’re doing, and also do cross-intros for people who are doing something interesting.
One interesting issue is, what do you talk to folks at these events about? Well, just come up with some angle you are thinking of – for a long time, mine was simply that I was from Seattle and worked in online advertising, and was looking at the games sector. If you can have a short conversation on something simple like that, it’s a good way to explore mutual interests. For many new startup folks, perhaps you have a small project you’re working on, or you’re looking into the Facebook economy, or whatever it is.
For me, I started out with ~250 or so connections on LinkedIn when I was in Seattle, and within 6 months, I had reached a multiple of that. Now I have my newsfeed on RSS, and I can quickly see what people have been up to lately.
Meet the Mafias
Like all great cities, the Bay Area is run by a small number of “Mafias.” The most famous, of course, is the PayPal mafia, but there’s also ex-Googlers, HotOrNot folks, Digg, YCombinator, and many others. Here’s a good article from TechCrunch listing specific names for people to get in touch with.
Many of these guys, given their success, end up starting investing vehicles – pay attention to these, since they are fascinating communities to understand. For PayPal there’s Founder’s Fund, Youniversity Ventures, and many angel investors. For Google, there’s Felicis Ventures and many angel investors as well.
Because some of these communities are very tight, they are hard to get to know until you have something interesting going, and something to offer in return. My general take on it is that ideally, you want to hang out with people who are a lot smarter than you ;-) Because of this, if you are hanging out with junior entrepreneurs all day (for example, the YCombinator folks) then you might not learn as much as if you spent time with people who have done a lot more than you.
I had the lucky opportunity to spend some time with PayPal-affiliated folks, as well as a few months hanging out at the Hi5 offices. All those guys are smarter than me, so I learned a lot ;-)
Keep a blog
I’ll make this one short, since for some it’s obvious: Blogs are a great way to stay relevant in the lives of a large group of people. There’s folks who I have met once or twice who occasionally read my blog, and it’s great, because it’s a low-work, highly-leveraged way for me to be part of the tech community’s conversation.
Need help?
And of course, if you read this and are thinking of moving to SF, shoot me a note at voodoo [at] gmail. I’m always particularly interested in meeting entrepreneurial engineers. Happy to help give more detail on any of the above.
iGoogle start pages: Vertical integration of the first, second, and Nth click

Start pages control traffic
There’s been some recent coverage of Google developing out their start page, iGoogle, and I thought it was very interesting – in particular, it fits with Google’s push to own the second click as well as the first. It’s a strategic thing for the company to do, since it lets them build on top of their "platform" – the search engine result page (SERP).
Daily usage websites
Think about the things that people do often, on a daily basis:
- Communicate (e-mail/Facebook/MySpace/etc)
- Entertainment (iTunes/YouTube/games/etc)
- News (blogs/CNN/etc)
- Reference (Google/Wikipedia/etc)
If you own the top property in one of these categories, it mean that every day, you have tens of millions of people visiting your site, which gives you a lot of leverage. This daily visit represents the so-called "first click" for each user on the internet. And from your site, depending on the context, these users then find subsequent destinations that they want to reach – this is the "second click."
Capturing user intent from the first-click/second-click transition
Of course, the transition from first click to second click is different for each channel:
- Communication – receiving a link from a friend
- Entertainment – seeing a "hot" video getting surfaced
- News – browsing the latest headlines
- Reference – looking for something specific and getting it as a result
Note that of the above, only reference is "pull" – the rest are "push." As a result, clicking on a link from a friend has less to do with your INTENT and more to do with your relationship with your friend. As a result, this type of interaction is harder to monetize. Compare this to a situation where you are specifying a specific thing you are looking for – these cases qualify the user to an extent where it becomes very easy to capture commercial intent.
Of course, Google already owns the first click for reference queries, and as a result, it only becomes logical for them to move both horizontally and vertically on the web. A horizontal move would be to capture the start page in news, communication, entertainment, etc. A vertical move would be for them to not just allow a search for "jobs 94025" but to actually give a form that a user can interact with to provide a secondary search on a specific job title. Each layer they can own allows them to further qualify the users, which makes it easier for them to cut out middlemen.
iGoogle+social = horizontal move?
Thus, you could argue that by incorporating more social activities, iGoogle is a horizontal move for Google. If iGoogle is successful in either creating their own social data or simply aggregating social network data (like FriendFeed does), then they remove a reason to check your MySpace or Facebook. Why do that when you can just go to iGoogle and see if you have any waiting messages? And while you’re there, you should do a search too ;-)
Viral loop coverage in Fast Company
Recent article on viral loops just came out from Fast Company: Ning’s Infinite Ambition.
I chatted with the writer, Adam Penenberg, when he was writing the article – we talked extensively about the history of viral marketing, starting from:
- chain letters
- style and fashion fads
- Tupperware
… and then how those techniques have now evolved on the web. The main differentiation, of course, being that you can really productize your distirbution strategy and incorporate it inside your user experience.
I’ve written much more about viral loops in a blog from last year.
Viral coefficient: What it does and does NOT measure

It’s easy to overemphasize viral user acquisition
I’ve recently been receiving a deluge of e-mail related to viral marketing – in particular, people sometimes represent it as a "magic bullet" to solving their startup’s problems. In fact, I’d argue that it’s merely one of many steps required to create a long-lasting, value-generating web property.
After all, the last thing you want to be is a fad, a one-hit wonder, or many of the other terms that are out there for rapidly spreading idea that quickly burnout.
Viral coefficient is only one metric of many
If anything, my overall point is to emphasize a hypothesis-driven, data-centric view of both the internal and external factors of your business. You need to build a sufficiently fine-grained model to expose the different levers available to you to optimize, verify, and repeat. If you care about pageviews, for example, but are only measuring the virality of your product, then you are missing out on all the other contributing variables in your business.
To summarize – metrics like the viral coefficient give you understanding of:
- For every user coming into your site, how many friends do they bring?
However, they don’t give you an understanding of:
- How long will it take for you to saturate the entire network of users?
- Do your customers love your product? Does it stimulate other positive emotions?
- Is your product sticky? Does it generate a lot of pageviews?
- Where does your traffic monetize well? And what methods of monetization work best?
- When and how does your product fit into the lives of your customers?
- Is your market big enough? Can your startup grow to be a billion+ business?
- etc.
The point is, if you’re trying to create an equation for revenue, where the virality is one part of the business – don’t be lazy. Build models and conduct experiments left and right on your product, so that you are always iterating.
Summarizing my undergrad degree in one statement
For some, this might seem like a disaster – an overflow of data. That’s absolutely a danger, and this is exactly when you have to start making smart choices to understand what variables are important to measure and which ones aren’t. Folks like engineers, statisticians, physicists, and other applied sciences will relate to this thought.
My undergrad degree was in a variation of Applied Math, and when describing to my friends what I learned, I often say I didn’t learn much beyond one phrase:
All mathematical models of the world are flaws, yet useful in their own way
Any mathy types that want to swap notes on viral marketing and user retention, feel free to shoot me an -mail ;-) I’m always curious to see how other people are modeling their traffic.

These are great points, and I agree with these issues as difficulties in applying LTV. The overall gist is that when you have interactions between users, all of a sudden the dependencies that are caused become difficult to measure.
Let’s talk about how to think about assigning credit based on those dependencies.
Assigning credit in LTV calculations is the hard part
Even in the most simple case for assigning credit in the LTV calculation, there are problems. Here’s the smallest example, in which one might ask:
Well, the answer to this question is actually quite complicated. First off, it depends on whether or not User A is likely to have that pageview anyway. That this, even if this content uploaded by User B didn’t exist, perhaps User A would be bored anyway and would have consumed that piece of content. In the opposite scenario, if User A came to the site for the express purpose of viewing User B’s content, then User B ought to get a lot of the credit.
Similarly, a case like this exists on the user acquisition side. The question in that case is:
You think they would, at least a bit, but it ultimately depends on whether or not B, C, and D were going to end up on the site anyway. If your acquisition is great, and you would likely have gotten them through some other acquisition scenario, then it doesn’t seem like A should get much credit. But if they are incremental users, then it’s great, and A should be rewarded.
The point is, a lot of this exercise becomes about figuring out the incremental value. You’re trying to extricate the value that would have already been there versus the new value that gets created by a user.
That’s a very philosophical question, I know ;-)
Conclusion
To summarize the blog post above:
Suggestions and comments are always welcome.